Code
p <- forecast::autoplot(TSstudio::Michigan_CS) +
xlab("") +
ylab("Index")
plotly::ggplotly(p)The goal of this lecture is to introduce time series and their common components. You should become confident in identifying and characterizing trends, seasonal and other variability based on visual analysis of time series plots and plots of autocorrelation functions.
Objectives
Reading materials
‘A time series is a set of observations \(Y_t\), each one being recorded at a specific time \(t\)’ (Brockwell and Davis 2002). The index \(t\) will typically refer to some standard unit of time, e.g., seconds, hours, days, weeks, months, or years.
‘A time series is a collection of observations made sequentially through time’ (Chatfield 2000).
A stochastic process is a sequence of random variables \(Y_t\), \(t = 1, 2, \dots\) indexed by time \(t\), which can be written as \(Y_t\), \(t \in [1,T]\). A time series is a realization of a stochastic process.
We shall frequently use the term time series to mean both the data and the process.
Let’s try to describe the patterns we see in Figure 2.1, Figure 2.2, and Figure 2.3.
p <- forecast::autoplot(TSstudio::Michigan_CS) +
xlab("") +
ylab("Index")
plotly::ggplotly(p)ggplot2::autoplot(JohnsonJohnson) +
xlab("") +
ylab("Earnings per share (USD)")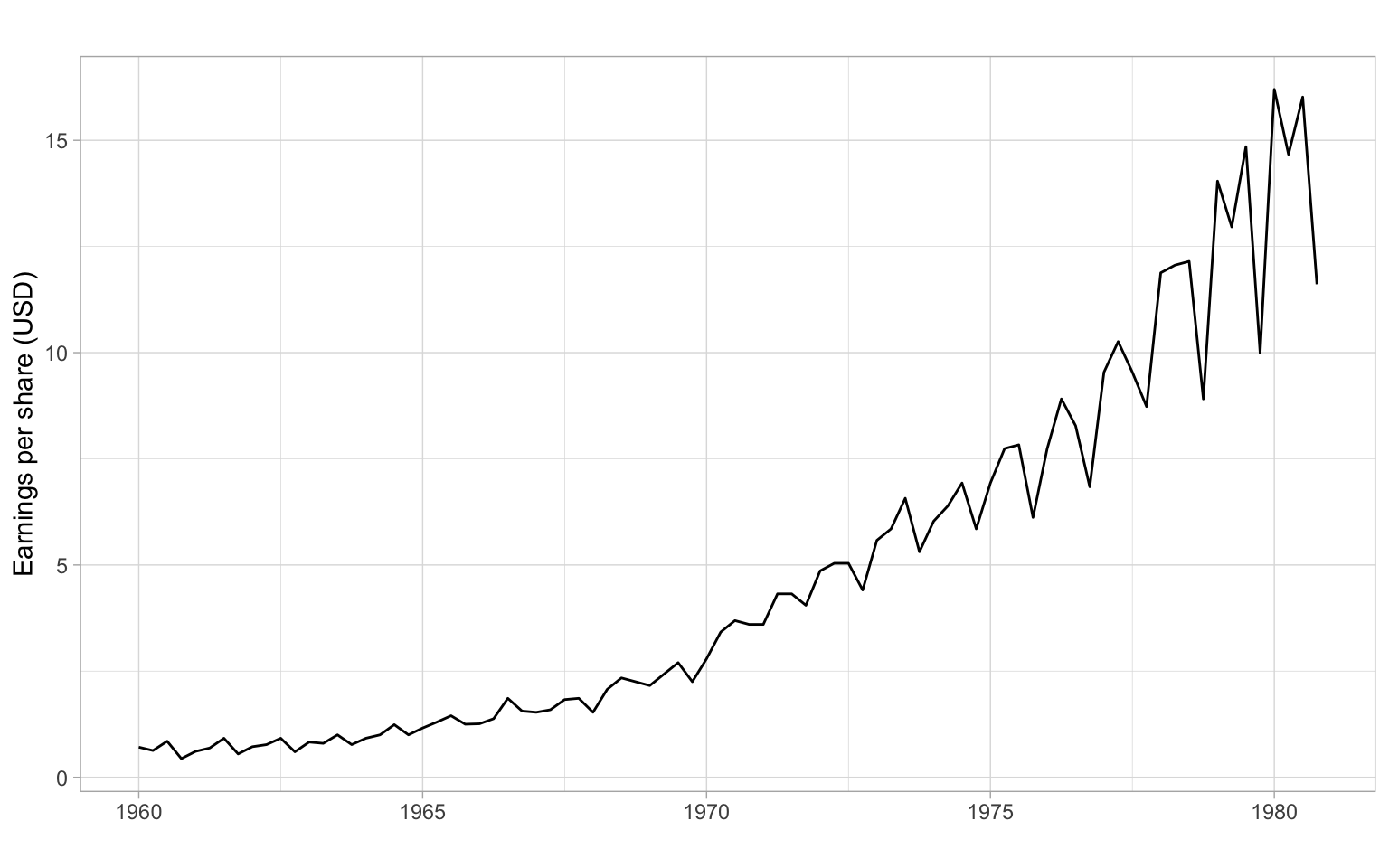
In this course, we will be interested in modeling time series to learn more about their properties and to forecast (predict) future values of \(Y_t\), i.e., values of \(Y_t\) for \(t\) beyond the end of the data set. Typically, we will use the historical data (or some appropriate subset of it) to build our forecasting models.
A time series can generally be expressed as a sum or product of four distinct components: \[ Y_t = M_t + S_t + C_t + \epsilon_t \] or \[ Y_t = M_t \cdot S_t \cdot C_t \cdot \epsilon_t, \] where
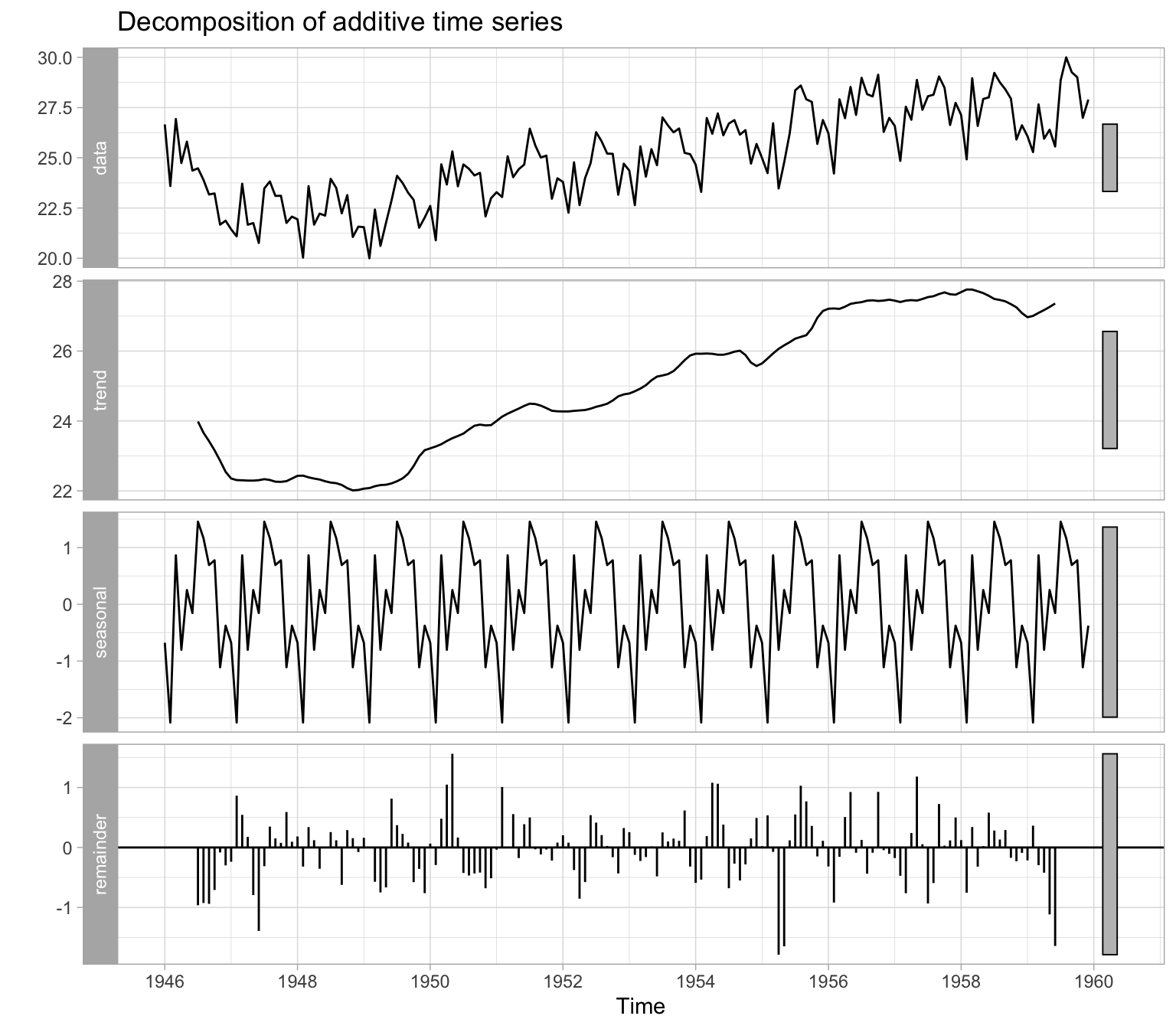
Figure 2.4 illustrates an automatic decomposition, however, because the user has too little control over how the decomposition is done, this function is not recommended. We will talk about the alternatives in the next lecture.
There are two general classes of forecasting models.
Univariate time series models include different types of exponential smoothing, trend models, autoregressive models, etc. The characteristic feature of these models is that we need only one time series to start with (\(Y_t\)), then we can build a regression of this time series over time (\(Y_t \sim t\)) for estimating the trend or, for example, an autoregressive model (‘auto’ \(=\) self). In the autoregressive approach, the current value \(Y_t\) is modeled as a function of the past values: \[ Y_t = f(Y_{t-1}, Y_{t-2}, \dots, Y_{t-p}) + \epsilon_t. \tag{2.1}\] A linear autoregressive model has the following form (assume that function \(f(\cdot)\) is a linear parametric function, with parameters \(\phi_0, \phi_1, \dots, \phi_p\)): \[ Y_t = \phi_0 + \phi_1 Y_{t-1} + \phi_2 Y_{t-2} + \dots +\phi_p Y_{t-p} + \epsilon_t. \]
Multivariate models involve additional covariates (a.k.a. regressors, predictors, or independent variables) \(X_{1,t}, X_{2,t}, \dots, X_{k,t}\). A multivariate time series model can be as simple as the multiple regression \[ Y_t = f(X_{1,t}, X_{2,t}, \dots, X_{k,t}) + \epsilon_t, \] or involve lagged values of the response and predictors: \[ \begin{split} Y_t = f(&X_{1,t}, X_{2,t}, \dots, X_{k,t}, \\ &X_{1,t-1}, X_{1,t-2}, \dots, X_{1,t-q1}, \\ &\dots\\ &X_{k,t-1}, X_{k,t-2}, \dots, X_{k,t-qk}, \\ &Y_{t-1}, Y_{t-2}, \dots, Y_{t-p}) + \epsilon_t, \end{split} \tag{2.2}\] where \(p\), \(q1, \dots, qk\) are the lags. We can start the analysis with many variables and build a forecasting model as complex as Equation 2.2, but remember that a simpler univariate model may also work well. We should create an appropriate univariate model (like in Equation 2.1) to serve as a baseline, then compare the models’ performance on some out-of-sample data, as described in Chapter 12.
ggplot2::autoplot(sunspots) +
xlab("") +
ylab("Sunspot number")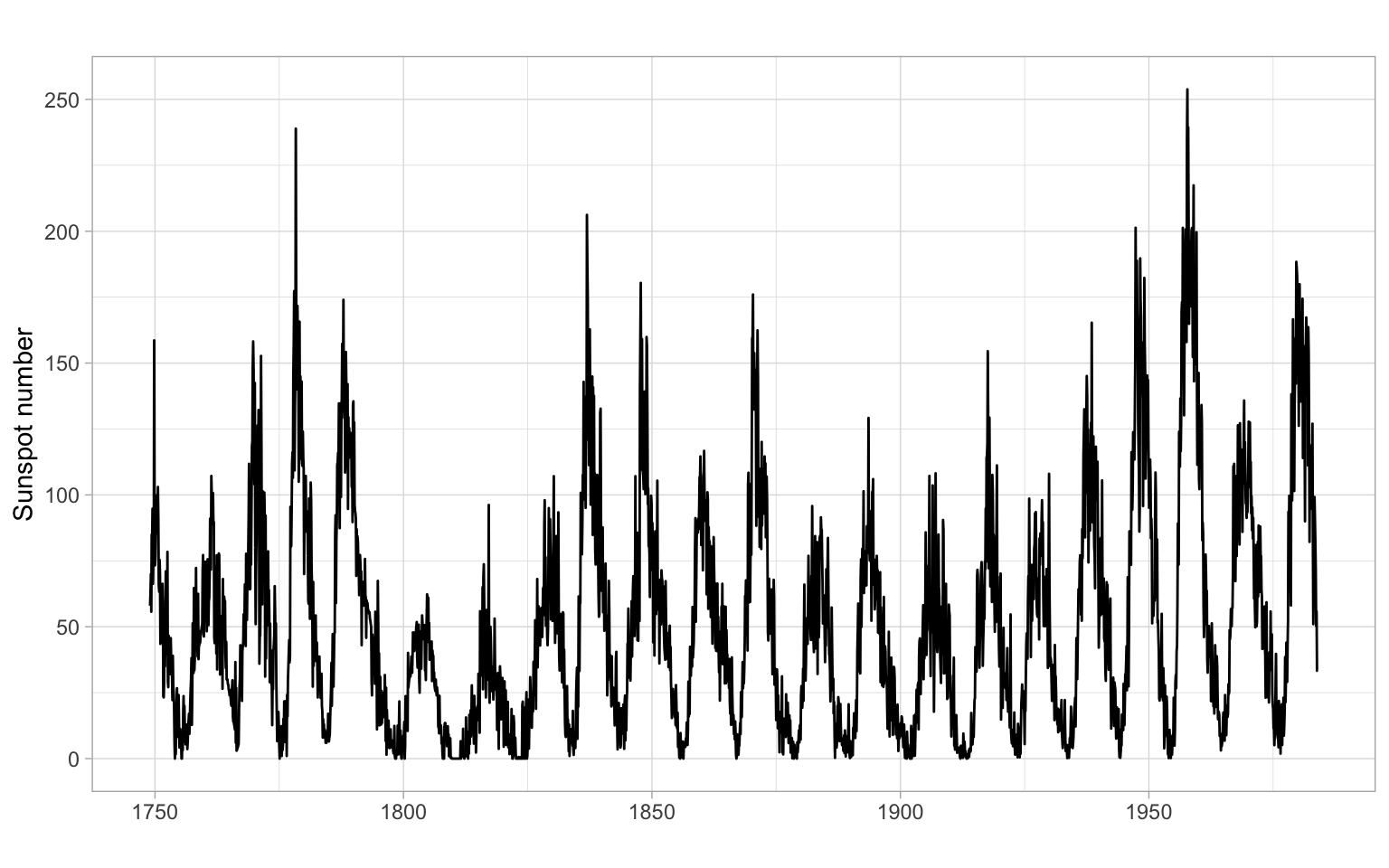
ggplot2::autoplot(lynx) +
xlab("") +
ylab("Number of lynx trappings")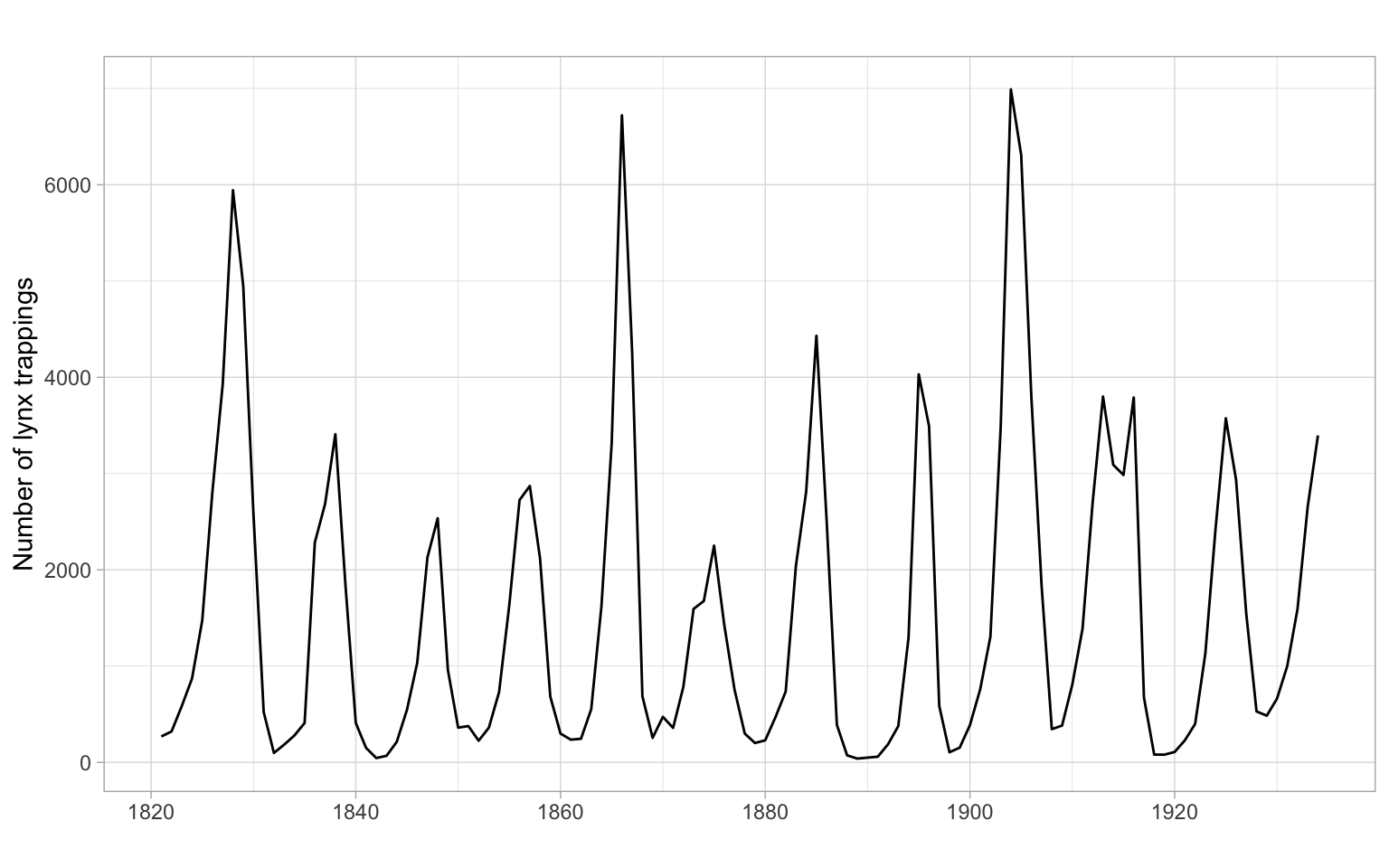
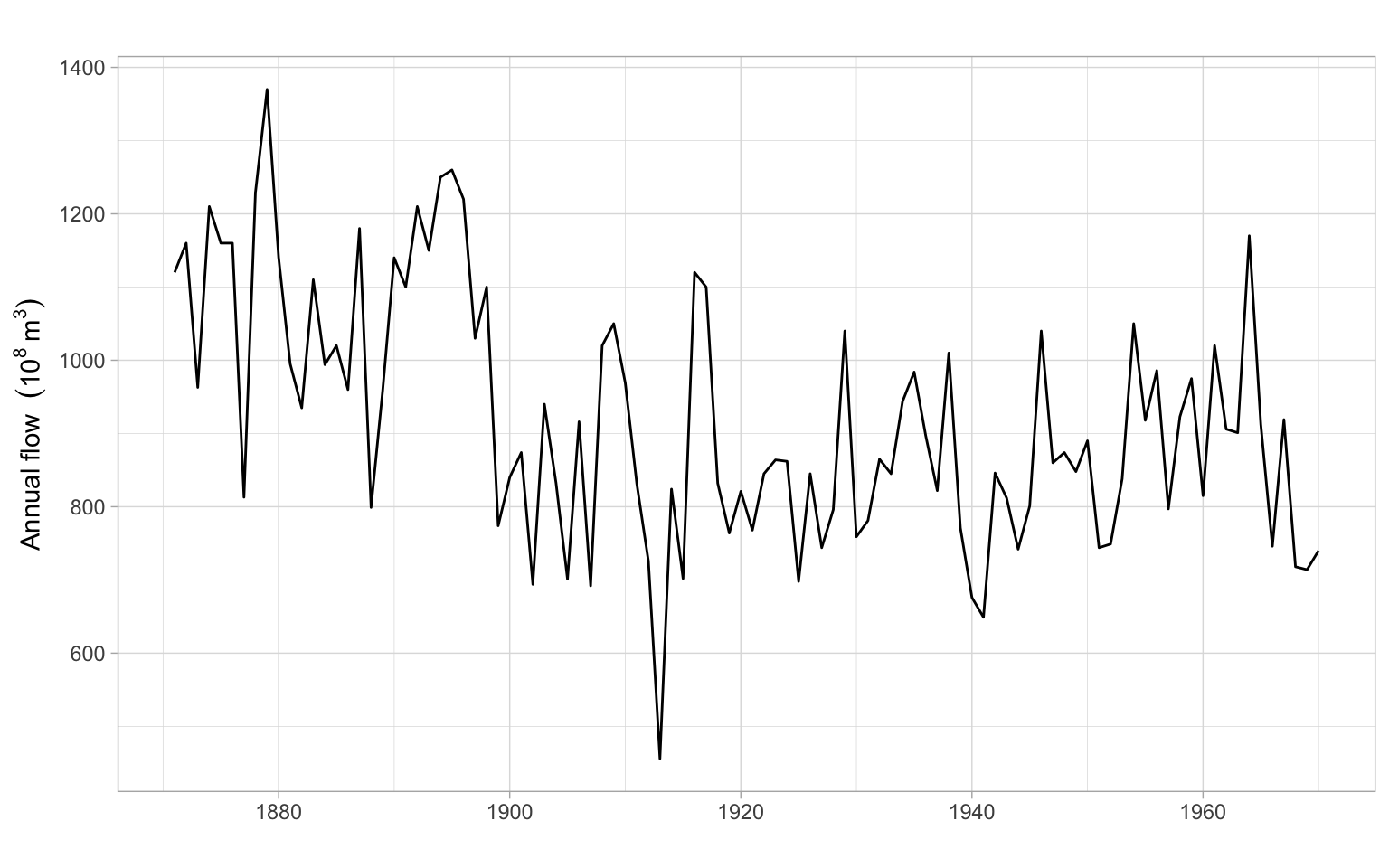
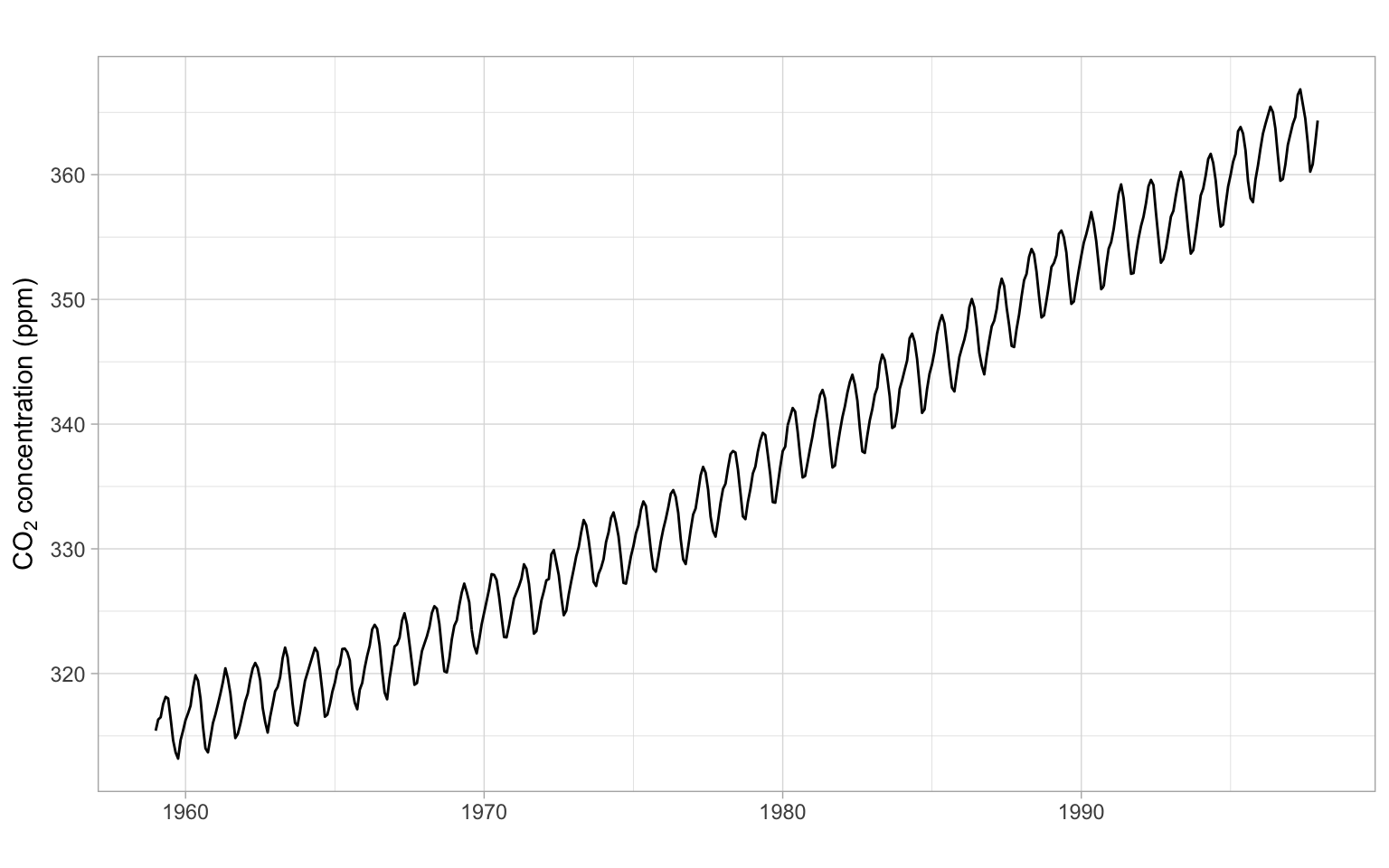
ggplot2::autoplot(Ecdat::Consumption[,"yd"]/1000) +
xlab("") +
ylab("Income (thousand 1986 dollars)")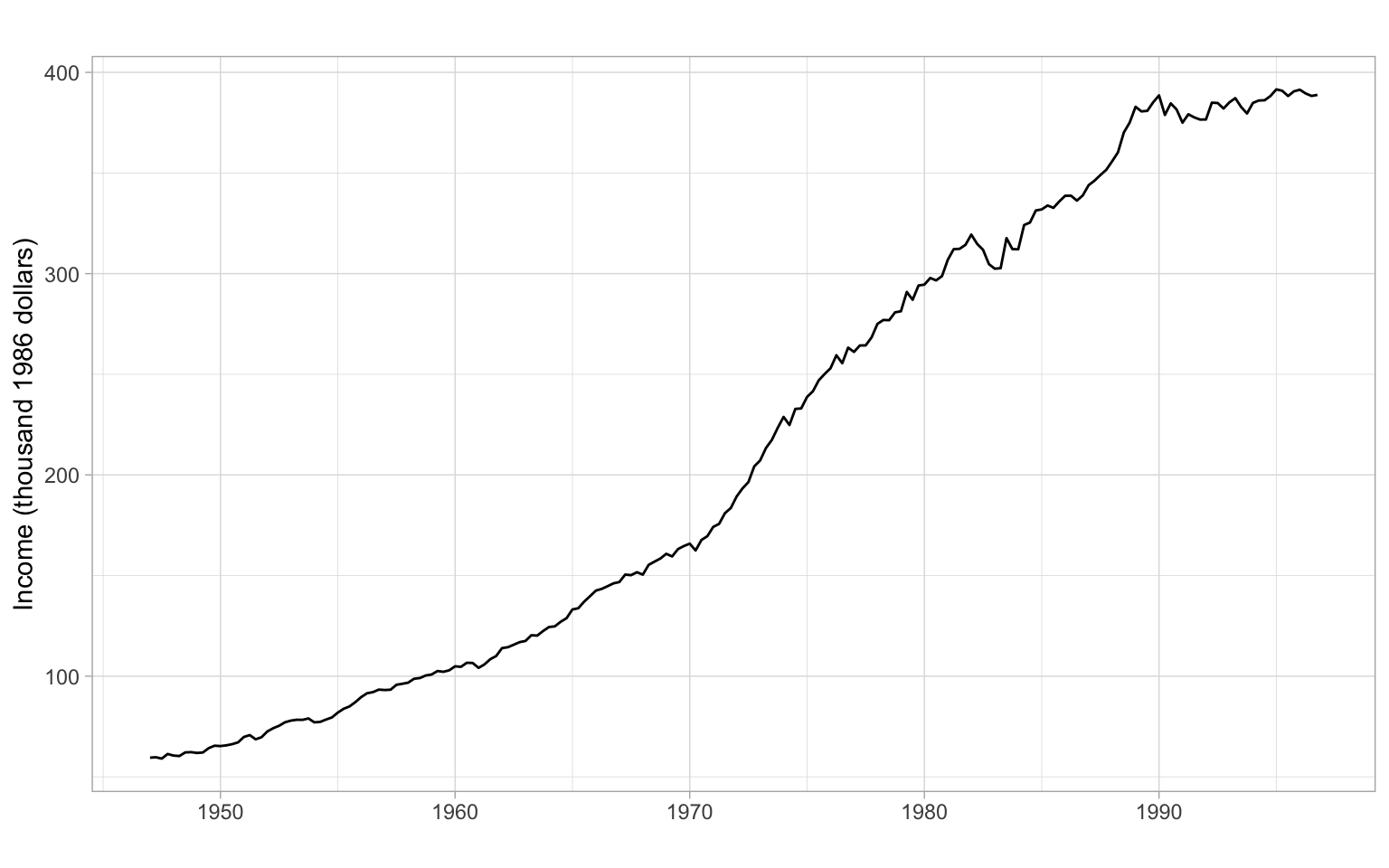
Recall that a random process is a sequence of random variables, so its model would be the joint distribution of these random variables \[ f_1(Y_{t_1}), \; f_2(Y_{t_1}, Y_{t_2}), \; f_3(Y_{t_1}, Y_{t_2}, Y_{t_3}), \dots \]
With sample data, usually, we cannot estimate so many parameters. Instead, we use only first- and second-order moments of the joint distributions, i.e., \(\mathrm{E}(Y_t)\) and \(\mathrm{E}(Y_tY_{t+h})\). In the case when all the joint distributions are multivariate normal (MVN), these second-order properties completely describe the sequence (we do not need any other information beyond the first two moments in this case).
It is time to give more formal definitions of stationarity. Loosely speaking, a time series \(X_t\) (\(t=0,\pm 1, \dots\)) is stationary if it has statistical properties similar to those of the time-shifted series \(X_{t+h}\) for each integer \(h\).
Let \(X_t\) be a time series with \(\mathrm{E}(X^2_t)<\infty\), then the mean function of \(X_t\) is \[ \mu_X(t)=\mathrm{E}(X_t). \]
The autocovariance function of \(X_t\) is \[ \gamma_X(r,s) = \mathrm{cov}(X_r,X_s) = \mathrm{E}[(X_r-\mu_X(r))(X_s-\mu_X(s))] \tag{2.3}\] for all integers \(r\) and \(s\).
Weak stationarity
\(X_t\) is (weakly) stationary if \(\mu_X(t)\) is independent of \(t\), and \(\gamma_X(t+h,t)\) is independent of \(t\) for each \(h\) (consider only the first two moments): \[ \begin{split} \mathrm{E}(X_t) &= \mu, \\ \mathrm{cov}(X_t, X_{t+h}) &= \gamma_X(h) < \infty. \end{split} \tag{2.4}\]
Strong stationarity
\(X_t\) is strictly stationary if (\(X_1, \dots, X_n\)) and (\(X_{1+h}, \dots, X_{n+h}\)) have the same joint distribution (consider all moments).
Strictly stationary \(X_t\) with finite variance \(\mathrm{E}(X_t^2) <\infty\) for all \(t\) is also weakly stationary.
If \(X_t\) is a Gaussian process, then strict and weak stationarity are equivalent (i.e., one form of stationarity implies the other).
In applications, it is usually very difficult if not impossible to verify strict stationarity. So in the vast majority of cases, we are satisfied with the weak stationarity. Moreover, we usually omit the word ‘weak’ and simply talk about stationarity (but have the weak stationary in mind).
Given the second condition of weak stationarity in Equation 2.4, we can write for stationary(!) time series the autocovariance function (ACVF) for the lag \(h\): \[ \gamma_X(h)= \gamma_X(t+h,t) = \mathrm{cov}(X_{t+h},X_t) \] and the autocorrelation function (ACF), which is the normalized autocovariance: \[ \rho_X(h)=\frac{\gamma_X(h)}{\gamma_X(0)}=\mathrm{cor}(X_{t+h},X_t). \]
The sample autocovariance function is defined as: \[
\hat{\gamma}_X(h)= n^{-1}\sum_{t=1}^{n-k}(x_{t+h}- \bar{x})(x_t - \bar{x}),
\] with \(\hat{\gamma}_X(h) = \hat{\gamma}_X(-h)\) for \(h = 0,1,\dots, n-1\). In R, use acf(X, type = "covariance").
The sample autocorrelation function is defined as (in R, use acf(X)): \[
\hat{\rho}_X(h)=\frac{\hat{\gamma}_X(h)}{\hat{\gamma}_X(0)}.
\]
acf(). Autocorrelations that reach outside this bound are then statistically significant. Note that in R as a rule of thumb the default maximal lag is \(10 \log_{10}(n)\), and the same \(n\) is used for the confidence bounds at all lags (however, in reality, samples of different sizes are used for each lag).The last property is yet another tool for testing autocorrelation in a time series, in addition to those listed in Chapter 1. Also, see the Ljung–Box test described below.
Ljung–Box test
Instead of testing autocorrelation at each lag, we can apply an overall test by Ljung and Box (1978):
\(H_0\): \(\rho(1) = \rho(2) = \dots = \rho(h) = 0\)
\(H_1\): \(\rho(j) \neq 0\) for some \(j \in \{1, 2, \dots, h\}\), where \(n > h\).
The Ljung–Box test statistic is given by \[
Q_h = n(n + 2) \sum_{j = 1}^h\frac{\hat{\rho}_j^2}{n - j}.
\] Under the null hypothesis, \(Q_h\) has a \(\chi^2\) distribution with \(h\) degrees of freedom. In R, this test is implemented in the function Box.test() with the argument type = "Ljung-Box" and in the function tsdiag().
The time series plot of births in Figure 2.11 shows a trend. The time series is not stationary. Thus, the calculated ACF is mostly useless (it is calculated under the assumption of stationarity), but we notice some periodicity in the ACF – it is a sign of periodicity in the time series itself (seasonality). Need to remove the trend (and seasonality) and repeat the ACF analysis.
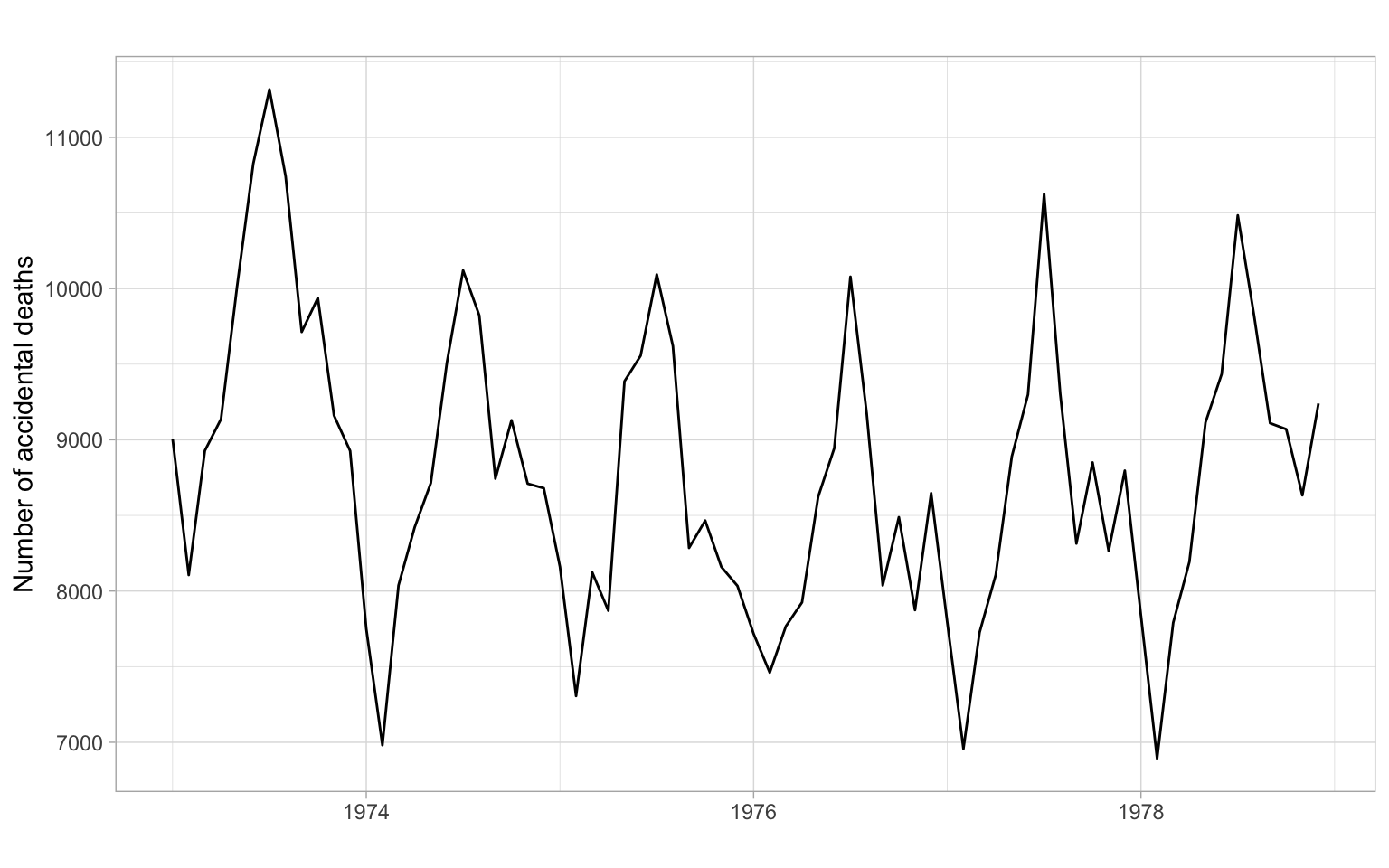
Compare with the plots for accidental deaths in Figure 2.12.
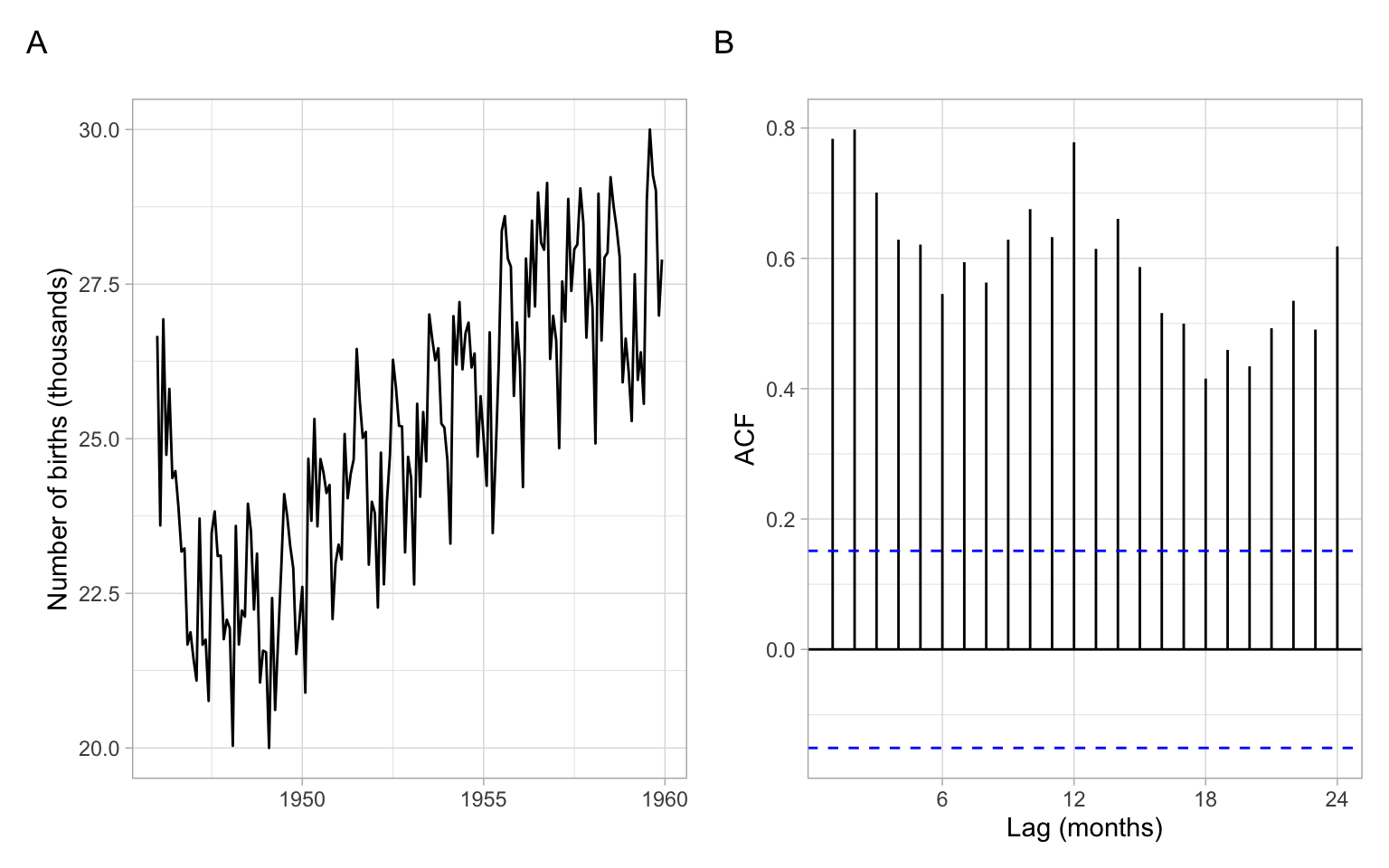
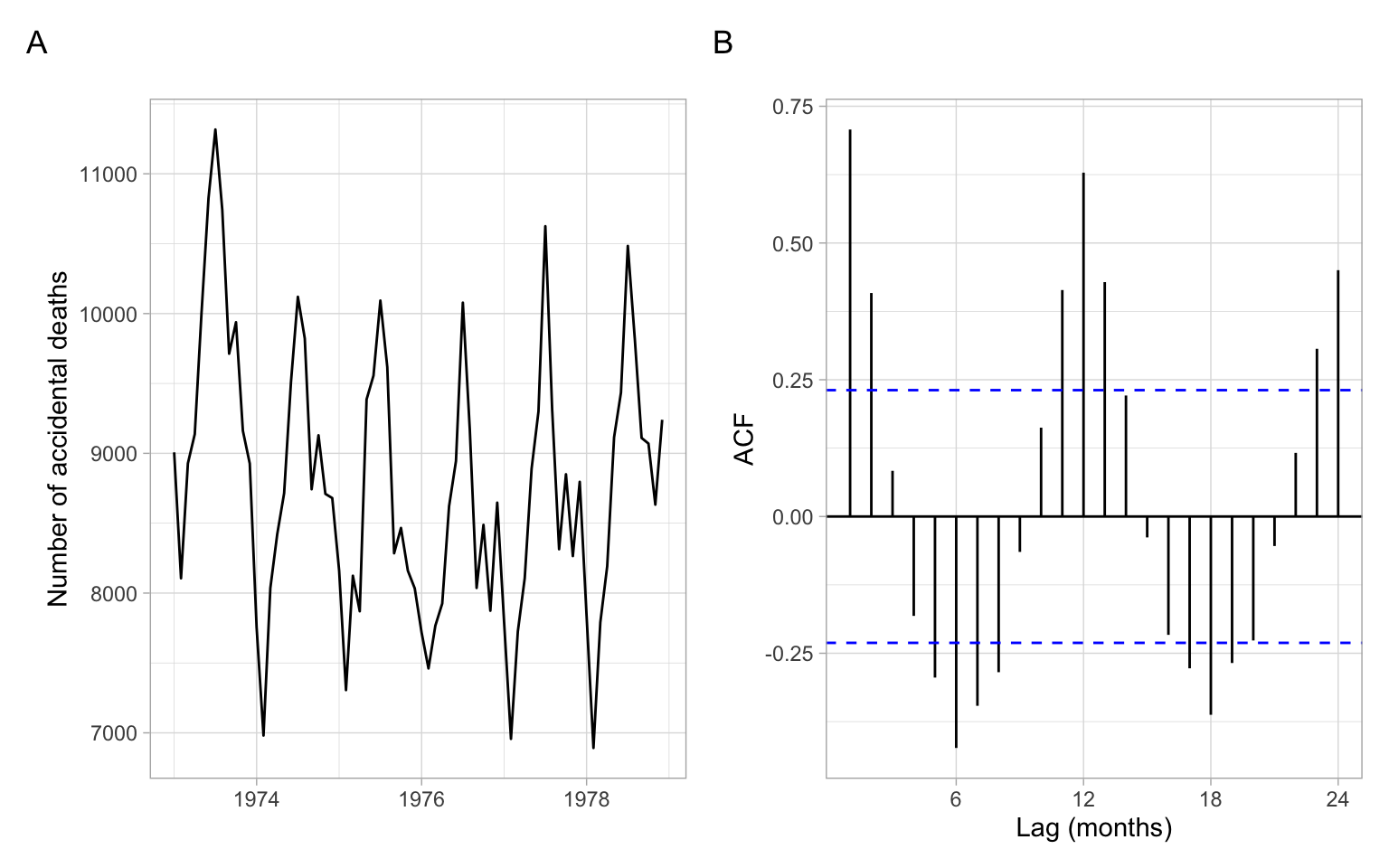
Figure 2.12 shows a slight trend of declining, then increasing deaths; the seasonal component in this time series is more dominant. The seasonal cycle of 12 months is clearly visible in the ACF.
In base-R plots, the lags in ACF plots are measured in the number of periods. The period information (or frequency, i.e., the number of observations per period) is saved in the format ts in R:
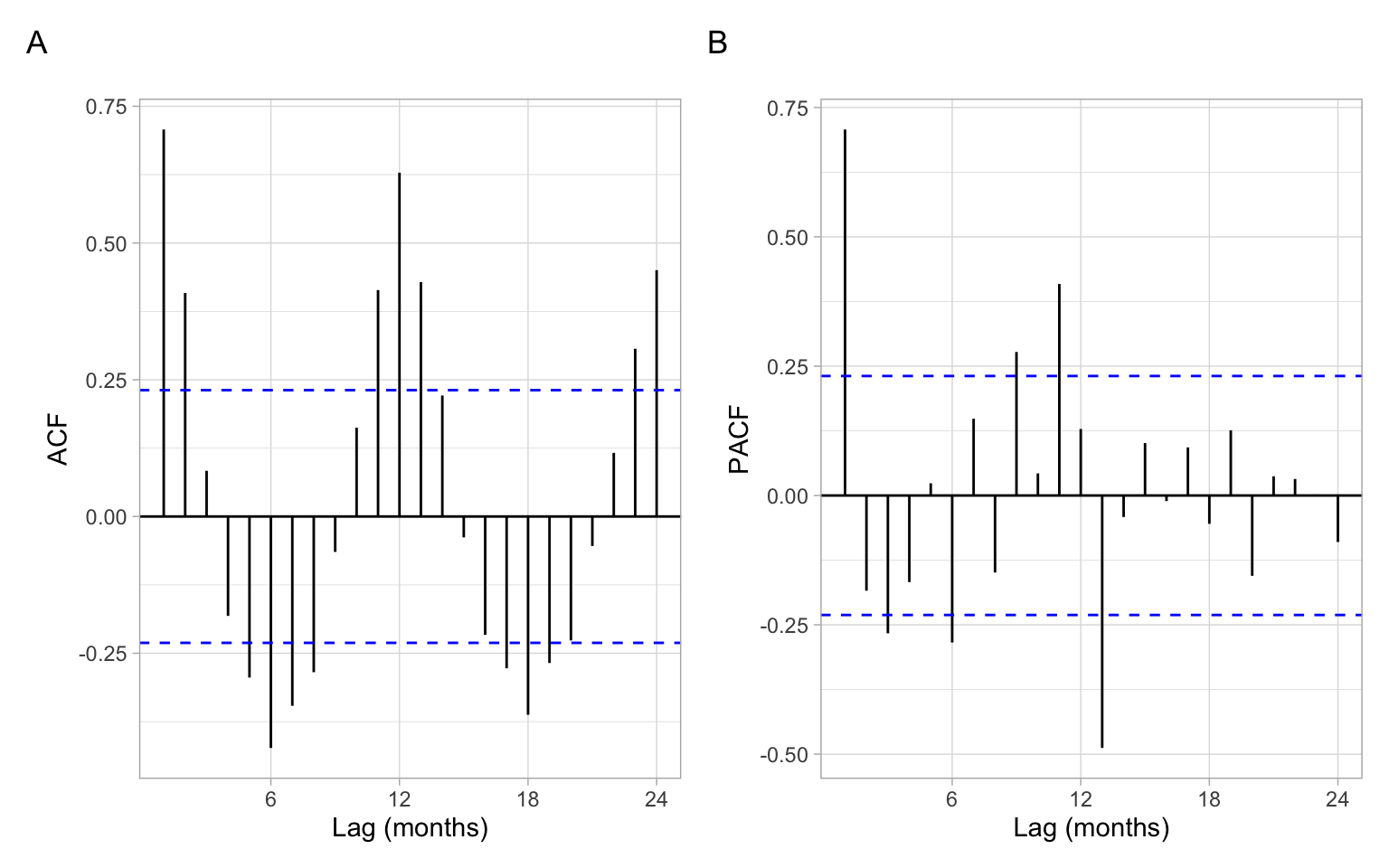
We don’t have to convert data to this format. If we plot the ACF of just a vector without these attributes, the values are the same, just the labels on the horizontal axis are different (Figure 2.13). For monthly data, as in the example here, the frequency is 12. Hence, here the ACF at lag 0.5 (Figure 2.13 A) means autocorrelation with the lag \(h=6\) months (Figure 2.13 B); lag 1 (Figure 2.13 A) corresponds to one whole period of \(h=12\) months (Figure 2.13 B), and so on.
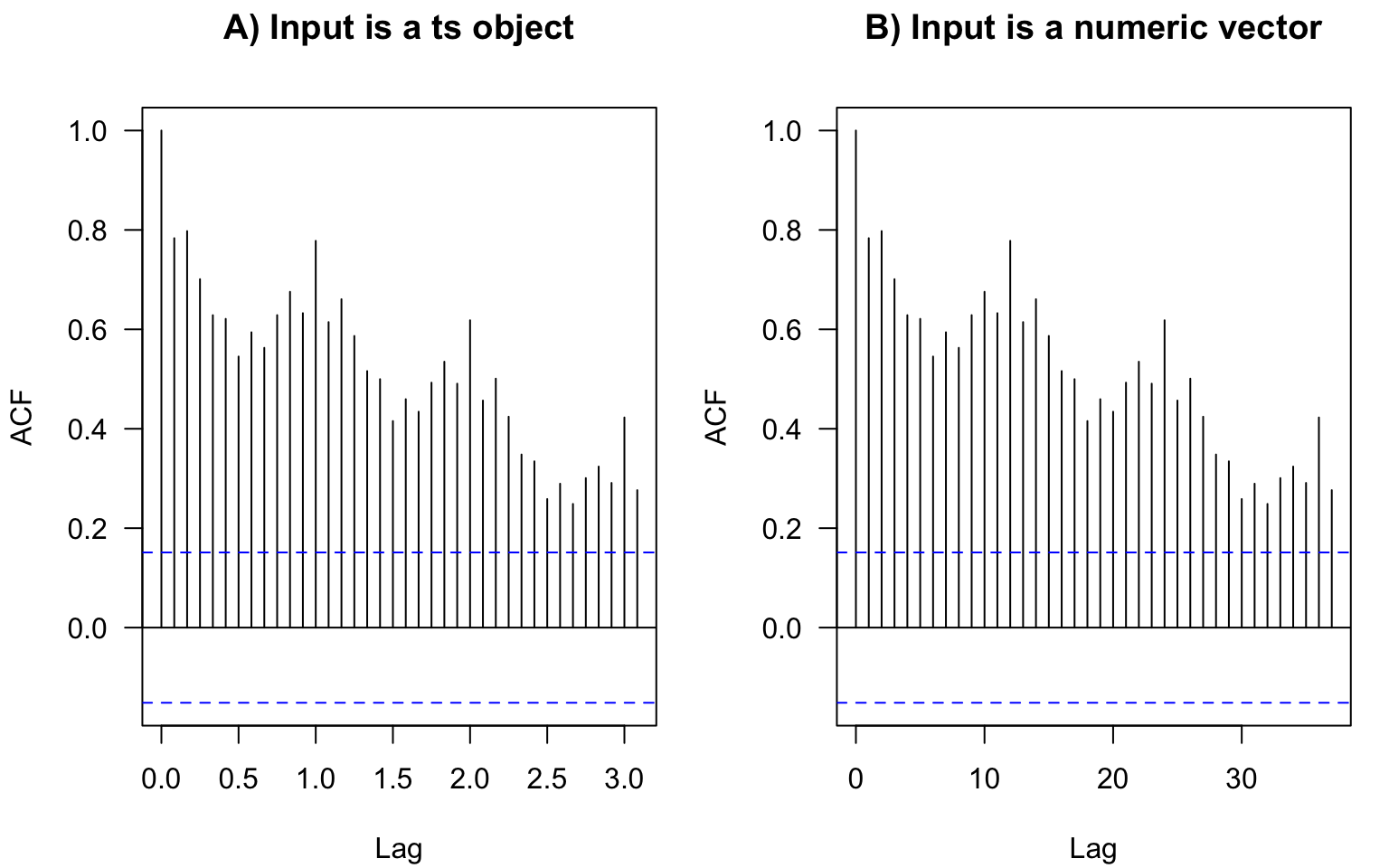
The ts objects in R cannot incorporate varying periods (e.g., different numbers of days or weeks because of leap years), therefore, we recommend using this format only for monthly or annual data. Setting frequency = 365.25 for daily data could be an option (although not very accurate) to accommodate leap years.
Converting to the ts format usually is not required for analysis. Most of the time we use plain numeric vectors and data frames in R.
Contributed R packages offer additional formats for time series, e.g., see the packages xts and zoo.
ACF measures the correlation between \(X_t\) and \(X_{t+h}\). The correlation can be due to a direct connection or through the intermediate steps \(X_{t+1}, X_{t+2}, \dots, X_{t+h-1}\). Partial ACF looks at the correlation between \(X_t\) and \(X_{t+h}\) once the effect of intermediate steps is removed.
Shumway and Stoffer (2011) and Shumway and Stoffer (2014) provide the following explanation of the concept.
Recall that if \(X\), \(Y\), and \(Z\) are random variables, then the partial correlation between \(X\) and \(Y\) given \(Z\) is obtained by regressing \(X\) on \(Z\) to obtain \(\hat{X}\), regressing \(Y\) on \(Z\) to obtain \(\hat{Y}\), and then calculating \[ \rho_{XY|Z} = \mathrm{cor}(X - \hat{X}, Y - \hat{Y}). \] The idea is that \(\rho_{XY|Z}\) measures the correlation between \(X\) and \(Y\) with the linear effect of \(Z\) removed (or partialled out). If the variables are multivariate normal, then this definition coincides with \(\rho_{XY|Z} = \mathrm{cor}(X,Y | Z)\).
The partial autocorrelation function (PACF) of a stationary process, \(X_t\), denoted \(\rho_{hh}\), for \(h = 1,2,\dots\), is \[ \rho_{11} = \mathrm{cor}(X_t, X_{t+1}) = \rho(1) \] and \[ \rho_{hh} = \mathrm{cor}(X_t - \hat{X}_t, X_{t+h} - \hat{X}_{t+h}), \; h\geqslant 2. \]
Both \((X_t - \hat{X}_t)\) and \((X_{t+h} - \hat{X}_{t+h})\) are uncorrelated with \(\{ X_{t+1}, \dots, X_{t+h-1}\}\). The PACF, \(\rho_{hh}\), is the correlation between \(X_{t+h}\) and \(X_t\) with the linear dependence of everything between them (intermediate lags), namely \(\{ X_{t+1}, \dots, X_{t+h-1}\}\), on each, removed.
In other notations, the PACF for the lag \(h\) and predictions \(P\) is \[ \rho_{hh} = \begin{cases} 1 & \text{if } h = 0 \\ \mathrm{cor}(X_t, X_{t+1}) = \rho(1) & \text{if } h = 1 \\ \mathrm{cor}(X_t - P(X_t | X_{t+1}, \dots, X_{t+h-1}), \\ \quad\;\; X_{t+h} - P(X_{t+h} | X_{t+1}, \dots, X_{t+h-1})) & \text{if } h > 1. \end{cases} \]
To obtain sample estimates of PACF in R, use pacf(X) or acf(X, type = "partial").
Correlation and partial correlation coefficients measure the strength and direction of the relationship, changing within \([-1, 1]\). The percent of explained variance for the case of two variables is measured by squared correlation (r-squared; \(R^2\); coefficient of determination) changing within \([0, 1]\), so a correlation of 0.2 means only 4% of variance explained by the simple linear relationship (regression). To report a partial correlation, for example, of 0.2 at lag 3, one could say something like ‘The partial autocorrelation at lag 3 (after removing the influence of the intermediate lags 1 and 2) is 0.2’ (depending on the application, the correlation of 0.2 can be considered weak or moderate strength) or ‘After accounting for autocorrelation at intermediate lags 1 and 2, the linear relationship at lag 3 can explain 4% of the remaining variability.’
The partial autocorrelation coefficients of i.i.d. time series are asymptotically distributed as \(N(0,1/n)\). Hence, for lags \(h > p\), where \(p\) is the optimal or true order of the partial autocorrelation, \(\rho_{hh} < 1.96/\sqrt{n}\) (assuming the confidence level 95%). This suggests using as a preliminary estimator of the order \(p\) the smallest value \(m\) such that \(\rho_{hh} < 1.96/\sqrt{n}\) for \(h > m\).
By plotting ACF and PACF (Figure 2.14), we observe that most of the temporal dependence (autocorrelation) in this time series is due to correlation with the immediately preceding values (see PACF at lag 1).
We have defined components of the time series including trend, periodic component, and unexplained variability (errors, residuals). Our goal will be to model trends and periodicity, extract them from the time series, then extract as much information as possible from the remainder, so the ultimate residuals become white noise.
White noise is a sequence of uncorrelated random variables with zero mean and finite variance. White noise is also an example of a weakly stationary time series. The i.i.d. noise is strictly stationary (all moments of the distribution stay identical through time), and i.i.d. noise with finite variance is also white noise.
Time-series dependence can be quantified using a (partial) autocorrelation function. We defined (P)ACF for stationary series; R functions also assume stationarity of the time series when calculating ACF or PACF.
After developing several models for modeling and forecasting time series, we can compare them quantitatively in cross-validation. For time series, it is typical to have the testing set (or a validation fold) to be after the training set. Models can be compared based on the accuracy of their point forecasts and interval forecasts.
Chapter 1: Prompt Chaining
Prompt chaining, sometimes referred to as Pipeline pattern, represents a powerful paradigm for handling intricate tasks when leveraging large language models (LLMs). Rather than expecting an LLM to solve a complex problem in a single, monolithic step, prompt chaining advocates for a divide-and-conquer strategy. The core idea is to break down the original, daunting problem into a sequence of smaller, more manageable sub-problems. Each sub-problem is addressed individually through a specifically designed prompt, and the output generated from one prompt is strategically fed as input into the subsequent prompt in the chain. This sequential processing technique inherently introduces modularity and clarity into the interaction with LLMs. By decomposing a complex task, it becomes easier to understand and debug each individual step, making the overall process more robust and interpretable. Each step in the chain can be meticulously crafted and optimized to focus on a specific aspect of the larger problem, leading to more accurate and focused outputs. The output of one step acting as the input for the next is crucial. This passing of information establishes a dependency chain, hence the name, where the context and results of previous operations guide the subsequent processing. This allows the LLM to build on its previous work, refine its understanding, and progressively move closer to the desired solution. Furthermore, prompt chaining is not just about breaking down problems; it also enables the integration of external knowledge and tools. At each step, the LLM can be instructed to interact with external systems, APIs, or databases, enriching its knowledge and abilities beyond its internal training data. This capability dramatically expands the potential of LLMs, allowing them to function not just as isolated models but as integral components of broader, more intelligent systems. The significance of prompt chaining extends beyond simple problem-solving. It serves as a foundational technique for building sophisticated AI agents. These agents can utilize prompt chains to autonomously plan, reason, and act in dynamic environments. By strategically structuring the sequence of prompts, an agent can engage in tasks requiring multi-step reasoning, planning, and decision-making. Such agent workflows can mimic human thought processes more closely, allowing for more natural and effective interactions with complex domains and systems.
Limitations of single prompts: For multifaceted tasks, using a single, complex prompt for an LLM can be inefficient, causing the model to struggle with constraints and instructions, potentially leading to instruction neglect where parts of the prompt are overlooked, contextual drift where the model loses track of the initial context, error propagation where early errors amplify, prompts which require a longer context window where the model gets insufficient information to respond back and hallucination where the cognitive load increases the chance of incorrect information. For example, a query asking to analyze a market research report, summarize findings, identify trends with data points, and draft an email risks failure as the model might summarize well but fail to extract data or draft an email properly. Enhanced Reliability Through Sequential Decomposition: Prompt chaining addresses these challenges by breaking the complex task into a focused, sequential workflow, which significantly improves reliability and control. Given the example above, a pipeline or chained approach can be described as follows: Initial Prompt (Summarization): “Summarize the key findings of the following market research report: [text].” The model’s sole focus is summarization, increasing the accuracy of this initial step. Second Prompt (Trend Identification): “Using the summary, identify the top three emerging trends and extract the specific data points that support each trend: [output from step 1].” This prompt is now more constrained and builds directly upon a validated output. Third Prompt (Email Composition): “Draft a concise email to the marketing team that outlines the following trends and their supporting data: [output from step 2].” This decomposition allows for more granular control over the process. Each step is simpler and less ambiguous, which reduces the cognitive load on the model and leads to a more accurate and reliable final output. This modularity is analogous to a computational pipeline where each function performs a specific operation before passing its result to the next. To ensure an accurate response for each specific task, the model can be assigned a distinct role at every stage. For example, in the given scenario, the initial prompt could be designated as “Market Analyst,” the subsequent prompt as “Trade Analyst,” and the third prompt as “Expert Documentation Writer,” and so forth. The Role of Structured Output: The reliability of a prompt chain is highly dependent on the integrity of the data passed between steps. If the output of one prompt is ambiguous or poorly formatted, the subsequent prompt may fail due to faulty input. To mitigate this, specifying a structured output format, such as JSON or XML, is crucial. For example, the output from the trend identification step could be formatted as a JSON object:
{ “trends”: [ { “trend_name”: “AI-Powered Personalization”, “supporting_data”: “73% of consumers prefer to do business with brands that use personal information to make their shopping experiences more relevant.” }, { “trend_name”: “Sustainable and Ethical Brands”, “supporting_data”: “Sales of products with ESG-related claims grew 28% over the last five years, compared to 20% for products without.” } ] }
This structured format ensures that the data is machine-readable and can be precisely parsed and inserted into the next prompt without ambiguity. This practice minimizes errors that can arise from interpreting natural language and is a key component in building robust, multi-step LLM-based systems. Practical Applications & Use Cases Prompt chaining is a versatile pattern applicable in a wide range of scenarios when building agentic systems. Its core utility lies in breaking down complex problems into sequential, manageable steps. Here are several practical applications and use cases: 1. Information Processing Workflows: Many tasks involve processing raw information through multiple transformations. For instance, summarizing a document, extracting key entities, and then using those entities to query a database or generate a report. A prompt chain could look like: Prompt 1: Extract text content from a given URL or document. Prompt 2: Summarize the cleaned text. Prompt 3: Extract specific entities (e.g., names, dates, locations) from the summary or original text. Prompt 4: Use the entities to search an internal knowledge base. Prompt 5: Generate a final report incorporating the summary, entities, and search results. This methodology is applied in domains such as automated content analysis, the development of AI-driven research assistants, and complex report generation. 2. Complex Query Answering: Answering complex questions that require multiple steps of reasoning or information retrieval is a prime use case. For example, “What were the main causes of the stock market crash in 1929, and how did government policy respond?” Prompt 1: Identify the core sub-questions in the user’s query (causes of crash, government response). Prompt 2: Research or retrieve information specifically about the causes of the 1929 crash. Prompt 3: Research or retrieve information specifically about the government’s policy response to the 1929 stock market crash. Prompt 4: Synthesize the information from steps 2 and 3 into a coherent answer to the original query. This sequential processing methodology is integral to developing AI systems capable of multi-step inference and information synthesis. Such systems are required when a query cannot be answered from a single data point but instead necessitates a series of logical steps or the integration of information from diverse sources. For example, an automated research agent designed to generate a comprehensive report on a specific topic executes a hybrid computational workflow. Initially, the system retrieves numerous relevant articles. The subsequent task of extracting key information from each article can be performed concurrently for each source. This stage is well-suited for parallel processing, where independent sub-tasks are run simultaneously to maximize efficiency. However, once the individual extractions are complete, the process becomes inherently sequential. The system must first collate the extracted data, then synthesize it into a coherent draft, and finally review and refine this draft to produce a final report. Each of these later stages is logically dependent on the successful completion of the preceding one. This is where prompt chaining is applied: the collated data serves as the input for the synthesis prompt, and the resulting synthesized text becomes the input for the final review prompt. Therefore, complex operations frequently combine parallel processing for independent data gathering with prompt chaining for the dependent steps of synthesis and refinement. 3. Data Extraction and Transformation: The conversion of unstructured text into a structured format is typically achieved through an iterative process, requiring sequential modifications to improve the accuracy and completeness of the output. Prompt 1: Attempt to extract specific fields (e.g., name, address, amount) from an invoice document. Processing: Check if all required fields were extracted and if they meet format requirements. Prompt 2 (Conditional): If fields are missing or malformed, craft a new prompt asking the model to specifically find the missing/malformed information, perhaps providing context from the failed attempt. Processing: Validate the results again. Repeat if necessary. Output: Provide the extracted, validated structured data. This sequential processing methodology is particularly applicable to data extraction and analysis from unstructured sources like forms, invoices, or emails. For example, solving complex Optical Character Recognition (OCR) problems, such as processing a PDF form, is more effectively handled through a decomposed, multi-step approach. Initially, a large language model is employed to perform the primary text extraction from the document image. Following this, the model processes the raw output to normalize the data, a step where it might convert numeric text, such as “one thousand and fifty,” into its numerical equivalent, 1050. A significant challenge for LLMs is performing precise mathematical calculations. Therefore, in a subsequent step, the system can delegate any required arithmetic operations to an external calculator tool. The LLM identifies the necessary calculation, feeds the normalized numbers to the tool, and then incorporates the precise result. This chained sequence of text extraction, data normalization, and external tool use achieves a final, accurate result that is often difficult to obtain reliably from a single LLM query. 4. Content Generation Workflows: The composition of complex content is a procedural task that is typically decomposed into distinct phases, including initial ideation, structural outlining, drafting, and subsequent revision Prompt 1: Generate 5 topic ideas based on a user’s general interest. Processing: Allow the user to select one idea or automatically choose the best one. Prompt 2: Based on the selected topic, generate a detailed outline. Prompt 3: Write a draft section based on the first point in the outline. Prompt 4: Write a draft section based on the second point in the outline, providing the previous section for context. Continue this for all outline points. Prompt 5: Review and refine the complete draft for coherence, tone, and grammar. This methodology is employed for a range of natural language generation tasks, including the automated composition of creative narratives, technical documentation, and other forms of structured textual content. 5. Conversational Agents with State: Although comprehensive state management architectures employ methods more complex than sequential linking, prompt chaining provides a foundational mechanism for preserving conversational continuity. This technique maintains context by constructing each conversational turn as a new prompt that systematically incorporates information or extracted entities from preceding interactions in the dialogue sequence. Prompt 1: Process User Utterance 1, identify intent and key entities. Processing: Update conversation state with intent and entities. Prompt 2: Based on current state, generate a response and/or identify the next required piece of information. Repeat for subsequent turns, with each new user utterance initiating a chain that leverages the accumulating conversation history (state). This principle is fundamental to the development of conversational agents, enabling them to maintain context and coherence across extended, multi-turn dialogues. By preserving the conversational history, the system can understand and appropriately respond to user inputs that depend on previously exchanged information. 6. Code Generation and Refinement: The generation of functional code is typically a multi-stage process, requiring a problem to be decomposed into a sequence of discrete logical operations that are executed progressively Prompt 1: Understand the user’s request for a code function. Generate pseudocode or an outline. Prompt 2: Write the initial code draft based on the outline. Prompt 3: Identify potential errors or areas for improvement in the code (perhaps using a static analysis tool or another LLM call). Prompt 4: Rewrite or refine the code based on the identified issues. Prompt 5: Add documentation or test cases. In applications such as AI-assisted software development, the utility of prompt chaining stems from its capacity to decompose complex coding tasks into a series of manageable sub-problems. This modular structure reduces the operational complexity for the large language model at each step. Critically, this approach also allows for the insertion of deterministic logic between model calls, enabling intermediate data processing, output validation, and conditional branching within the workflow. By this method, a single, multifaceted request that could otherwise lead to unreliable or incomplete results is converted into a structured sequence of operations managed by an underlying execution framework. 7. Multimodal and multi-step reasoning: Analyzing datasets with diverse modalities necessitates breaking down the problem into smaller, prompt-based tasks. For example, interpreting an image that contains a picture with embedded text, labels highlighting specific text segments, and tabular data explaining each label, requires such an approach. Prompt 1: Extract and comprehend the text from the user’s image request. Prompt 2: Link the extracted image text with its corresponding labels. Prompt 3: Interpret the gathered information using a table to determine the required output. Hands-On Code Example Implementing prompt chaining ranges from direct, sequential function calls within a script to the utilization of specialized frameworks designed to manage control flow, state, and component integration. Frameworks such as LangChain, LangGraph, Crew AI, and the Google Agent Development Kit (ADK) offer structured environments for constructing and executing these multi-step processes, which is particularly advantageous for complex architectures. For the purpose of demonstration, LangChain and LangGraph are suitable choices as their core APIs are explicitly designed for composing chains and graphs of operations. LangChain provides foundational abstractions for linear sequences, while LangGraph extends these capabilities to support stateful and cyclical computations, which are necessary for implementing more sophisticated agentic behaviors. This example will focus on a fundamental linear sequence. The following code implements a two-step prompt chain that functions as a data processing pipeline. The initial stage is designed to parse unstructured text and extract specific information. The subsequent stage then receives this extracted output and transforms it into a structured data format. To replicate this procedure, the required libraries must first be installed. This can be accomplished using the following command:
pip install langchain langchain-community langchain-openai langgraph
Note that langchain-openai can be substituted with the appropriate package for a different model provider. Subsequently, the execution environment must be configured with the necessary API credentials for the selected language model provider, such as OpenAI, Google Gemini, or Anthropic. import os from langchain_openai import ChatOpenAI from langchain_core.prompts import ChatPromptTemplate from langchain_core.output_parsers import StrOutputParser
llm = ChatOpenAI(temperature=0)
prompt_extract = ChatPromptTemplate.from_template( “Extract the technical specifications from the following text:” )
prompt_transform = ChatPromptTemplate.from_template( “Transform the following specifications into a JSON object with ‘cpu’, ‘memory’, and ‘storage’ as keys:” )
extraction_chain = prompt_extract | llm | StrOutputParser()
full_chain = ( {“specifications”: extraction_chain} | prompt_transform | llm | StrOutputParser() )
input_text = “The new laptop model features a 3.5 GHz octa-core processor, 16GB of RAM, and a 1TB NVMe SSD.”
final_result = full_chain.invoke({“text_input”: input_text})
print(“— Final JSON Output —”) print(final_result)
This Python code demonstrates how to use the LangChain library to process text. It utilizes two separate prompts: one to extract technical specifications from an input string and another to format these specifications into a JSON object. The ChatOpenAI model is employed for language model interactions, and the StrOutputParser ensures the output is in a usable string format. The LangChain Expression Language (LCEL) is used to elegantly chain these prompts and the language model together. The first chain, extraction_chain, extracts the specifications. The full_chain then takes the output of the extraction and uses it as input for the transformation prompt. A sample input text describing a laptop is provided. The full_chain is invoked with this text, processing it through both steps. The final result, a JSON string containing the extracted and formatted specifications, is then printed. Context Engineering and Prompt Engineering Context Engineering (see Fig.1) is the systematic discipline of designing, constructing, and delivering a complete informational environment to an AI model prior to token generation. This methodology asserts that the quality of a model’s output is less dependent on the model’s architecture itself and more on the richness of the context provided.
Fig.1: Context Engineering is the discipline of building a rich, comprehensive informational environment for an AI, as the quality of this context is a primary factor in enabling advanced Agentic performance. It represents a significant evolution from traditional prompt engineering, which focuses primarily on optimizing the phrasing of a user’s immediate query. Context Engineering expands this scope to include several layers of information, such as the system prompt, which is a foundational set of instructions defining the AI’s operational parameters—for instance, “You are a technical writer; your tone must be formal and precise.” The context is further enriched with external data. This includes retrieved documents, where the AI actively fetches information from a knowledge base to inform its response, such as pulling technical specifications for a project. It also incorporates tool outputs, which are the results from the AI using an external API to obtain real-time data, like querying a calendar to determine a user’s availability. This explicit data is combined with critical implicit data, such as user identity, interaction history, and environmental state. The core principle is that even advanced models underperform when provided with a limited or poorly constructed view of the operational environment. This practice, therefore, reframes the task from merely answering a question to building a comprehensive operational picture for the agent. For example, a context-engineered agent would not just respond to a query but would first integrate the user’s calendar availability (a tool output), the professional relationship with an email’s recipient (implicit data), and notes from previous meetings (retrieved documents). This allows the model to generate outputs that are highly relevant, personalized, and pragmatically useful. The “engineering” component involves creating robust pipelines to fetch and transform this data at runtime and establishing feedback loops to continually improve context quality. To implement this, specialized tuning systems can be used to automate the improvement process at scale. For example, tools like Google’s Vertex AI prompt optimizer can enhance model performance by systematically evaluating responses against a set of sample inputs and predefined evaluation metrics. This approach is effective for adapting prompts and system instructions across different models without requiring extensive manual rewriting. By providing such an optimizer with sample prompts, system instructions, and a template, it can programmatically refine the contextual inputs, offering a structured method for implementing the feedback loops required for sophisticated Context Engineering. This structured approach is what differentiates a rudimentary AI tool from a more sophisticated and contextually-aware system. It treats the context itself as a primary component, placing critical importance on what the agent knows, when it knows it, and how it uses that information. The practice ensures the model has a well-rounded understanding of the user’s intent, history, and current environment. Ultimately, Context Engineering is a crucial methodology for advancing stateless chatbots into highly capable, situationally-aware systems. At a Glance What: Complex tasks often overwhelm LLMs when handled within a single prompt, leading to significant performance issues. The cognitive load on the model increases the likelihood of errors such as overlooking instructions, losing context, and generating incorrect information. A monolithic prompt struggles to manage multiple constraints and sequential reasoning steps effectively. This results in unreliable and inaccurate outputs, as the LLM fails to address all facets of the multifaceted request. Why: Prompt chaining provides a standardized solution by breaking down a complex problem into a sequence of smaller, interconnected sub-tasks. Each step in the chain uses a focused prompt to perform a specific operation, significantly improving reliability and control. The output from one prompt is passed as the input to the next, creating a logical workflow that progressively builds towards the final solution. This modular, divide-and-conquer strategy makes the process more manageable, easier to debug, and allows for the integration of external tools or structured data formats between steps. This pattern is foundational for developing sophisticated, multi-step Agentic systems that can plan, reason, and execute complex workflows. Rule of thumb: Use this pattern when a task is too complex for a single prompt, involves multiple distinct processing stages, requires interaction with external tools between steps, or when building Agentic systems that need to perform multi-step reasoning and maintain state. Visual summary
Fig. 2: Prompt Chaining Pattern: Agents receive a series of prompts from the user, with the output of each agent serving as the input for the next in the chain. Key Takeaways Here are some key takeaways: Prompt Chaining breaks down complex tasks into a sequence of smaller, focused steps. This is occasionally known as the Pipeline pattern. Each step in a chain involves an LLM call or processing logic, using the output of the previous step as input. This pattern improves the reliability and manageability of complex interactions with language models. Frameworks like LangChain/LangGraph, and Google ADK provide robust tools to define, manage, and execute these multi-step sequences. Conclusion By deconstructing complex problems into a sequence of simpler, more manageable sub-tasks, prompt chaining provides a robust framework for guiding large language models. This “divide-and-conquer” strategy significantly enhances the reliability and control of the output by focusing the model on one specific operation at a time. As a foundational pattern, it enables the development of sophisticated AI agents capable of multi-step reasoning, tool integration, and state management. Ultimately, mastering prompt chaining is crucial for building robust, context-aware systems that can execute intricate workflows well beyond the capabilities of a single prompt.
References
LangChain Documentation on LCEL: https://python.langchain.com/v0.2/docs/core_modules/expression_language/
LangGraph Documentation: https://langchain-ai.github.io/langgraph/ Prompt Engineering Guide - Chaining Prompts: https://www.promptingguide.ai/techniques/chaining
OpenAI API Documentation (General Prompting Concepts): https://platform.openai.com/docs/guides/gpt/prompting Crew AI Documentation (Tasks and Processes): https://docs.crewai.com/
Google AI for Developers (Prompting Guides): https://cloud.google.com/discover/what-is-prompt-engineering?hl=en Vertex Prompt Optimizer https://cloud.google.com/vertex-ai/generative-ai/docs/learn/prompts/prompt-optimizer