Scaling Smart Grids with Transfer Learning and DRL
How knowledge transfer between smart grids speeds up learning and reduces energy costs
Introduction
As renewable energy integration accelerates, modern power grids face mounting complexity in maintaining stability and efficiency. Deep Reinforcement Learning (DRL) has emerged as a powerful technique for Volt-Var Control (VVC) — regulating voltage levels across the distribution grid — but its Achilles’ heel lies in expensive retraining.
Every new grid topology or environment demands retraining from scratch, costing time, data, and computational energy.
In our latest work, presented at the Workshop on Autonomous Energy Systems (GRID-EDGE 2025), we introduce a Transfer Learning (TL)-based DRL framework that enables policy reuse across different grid configurations — cutting training time by 98.14% while improving performance by 69.51%.
Core Idea: Transfer Learning Meets DRL
Traditional DRL systems learn from scratch. TL-DRL systems, however, transfer policy knowledge from a source grid (e.g., IEEE-123 Bus) to a target grid (e.g., IEEE-13 Bus).
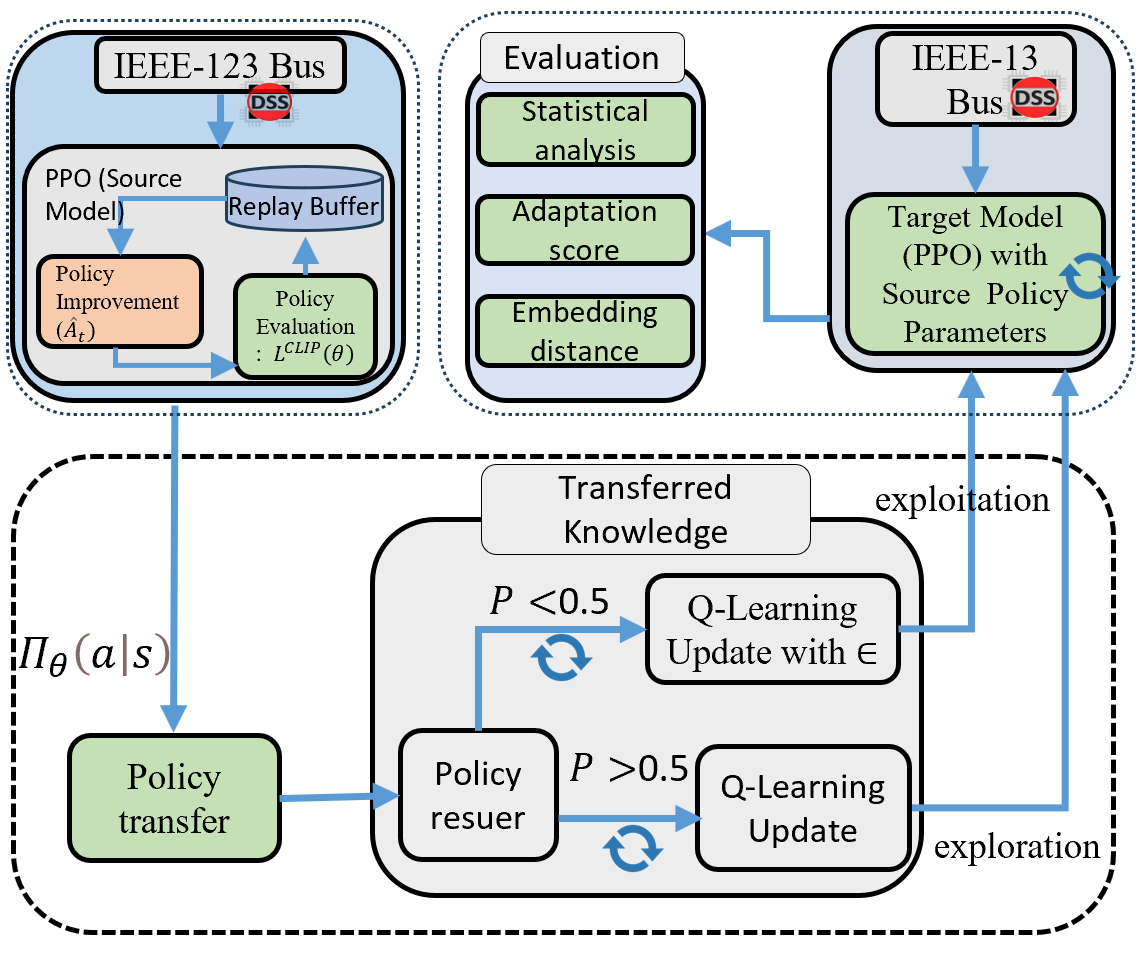
This approach allows agents to start smarter, building upon previously learned representations rather than reinventing them. The heart of this system is a policy reuse classifier, a small neural network that decides when the previously learned policy should be reused or adapted.
How It Works
The framework operates in three phases:
1. Source Training
A DRL agent, using the Proximal Policy Optimization (PPO) algorithm, learns to manage the IEEE-123 Bus system. The policy parameters, denoted as θₛₒᵤᵣcₑ, optimize voltage levels and reactive power flow according to ANSI C84.1-2020 voltage standards.
2. Policy Reuse Classifier
We train a binary classifier that predicts the probability of reusing a learned policy: [ P(|) = (f_()) ] If this probability exceeds 0.5, the source policy is transferred directly; otherwise, the agent retrains in the target environment.
3. Target Adaptation
The target model (θₜₐᵣgₑₜ) adapts to the IEEE-13 Bus through fine-tuning and Q-value updates, balancing exploration and exploitation dynamically: [ = P(|) ] This adaptive mechanism allows the agent to decide when to trust previous experience and when to explore new strategies.
Experimental Setup
We implemented the system in OpenDSS using the PowerGym RL environment.
The source policy (IEEE-123 Bus) was trained for 20,000 iterations, taking 313 seconds.
The TL-enhanced target model (IEEE-13 Bus) adapted in just 9.6 seconds — compared to 518 seconds when trained from scratch.
| Metric | Training with TL | Without TL |
|---|---|---|
| Mean Reward | -8.310 | -27.256 |
| Training Time | 9.62 s | 518.38 s |
| T-Statistic | 102.93 | — |
| P-Value | 6.38 | — |
| TAS (Task Adaptation Score) | 72.78 | — |
| Embedding Distance (ED) | 31.11 | — |
These results show that TL not only speeds up convergence but also produces a statistically significant performance improvement.
Key Insights
- Efficiency Leap — TL cut training time by 98%, accelerating grid simulation workflows dramatically.
- Policy Robustness — The classifier effectively distinguished when to reuse policies, preserving stability in unseen grid configurations.
- Scalability — The approach generalizes across systems of different complexity, paving the way for large-scale adaptive control.
Broader Impact
The proposed TL-DRL framework makes reinforcement learning practical for real-world grid management.
By leveraging existing knowledge, utilities can deploy smarter and faster control policies, reducing both operational costs and computational footprints — a critical step toward sustainable AI-driven power systems.
What’s Next
Our next goal is to scale TL across multiple grid sizes — from micro-grids to regional networks — and to integrate physics-informed constraints that further improve generalization.
We also aim to extend this framework to federated and collaborative learning paradigms, allowing distributed grids to share intelligence securely.
Reference
Kundan Kumar, Ravikumar Gelli.
“Transfer Learning Enhanced Deep Reinforcement Learning for Volt-Var Control in Smart Grids.”
Workshop on Autonomous Energy Systems, GRID-EDGE 2025.
We developed a TL-DRL framework, as shown in Fig.~\(\ref{fig:A2C}\), which involves transferring policy knowledge from one distribution grid to another. Additionally, we have created a policy reuse classifier to determine whether to transfer the policy knowledge from the IEEE-123 Bus to the IEEE-13 Bus system and conducted an impact analysis.
About the talk
We developed a TL-DRL framework, as shown in Fig.~\(\ref{fig:A2C}\), which involves transferring policy knowledge from one distribution grid to another. Additionally, we have created a policy reuse classifier to determine whether to transfer the policy knowledge from the IEEE-123 Bus to the IEEE-13 Bus system and conducted an impact analysis. \[\begin{equation}\label{eq:ppo_objective} \theta_{\text{source}} = \arg \max_{\theta} \mathbb{E}_{\tau \sim \pi_{\theta}} \left[ \sum_{t=0}^{T} \gamma^t r_t - \beta \text{CLIP}(\theta) \right] \end{equation}\] The \(\theta_{\text{source}}\) is trained with the DRL algorithm on the IEEE-123 Bus, which regulates the VVC voltage profiles within permissible limits.
While \(\theta_{\text{target}}\) is the model which transferred the knowledge \(\theta_{\text{source}}\) and adapts well in the \(\theta_{\text{target}}\) domain. \[\begin{equation}\label{eq:target_theta} \theta_{\text{target}} = \begin{cases} \begin{aligned} \theta_{\text{source}}\; & \text{if } P(\text{Reuse}|\text{Observation}) > 0.5 \end{aligned} \\ \arg \max_{\theta} \mathbb{E}_{\tau \sim \pi_{\theta}} \left[ \sum_{t=0}^{T} \gamma^t r_t \right] & \text{otherwise} \end{cases} \end{equation}\]