Research Scientist Interview Guide
Research Scientist Interview Guide
Overview
This guide provides a practical framework to prepare for Research Scientist roles in academia, industry research labs (FAANG, OpenAI, DeepMind, Anthropic, NVIDIA), and national labs. It blends personal experience with hiring-manager expectations and common evaluation rubrics.
GitHub repository: Code
Data Science Notes: Data Science Intro
Statistical Learning Notes: Statistical Analysis
What interviewers evaluate
- Research impact: novelty, citations/adoption, reproducibility, clarity of problem–method–evidence chain.
- Technical depth: math/ML fundamentals, experimental rigor, ablation thinking, error analysis.
- Systems sense: how ideas become products—data, infra, metrics, reliability, safety & ethics.
- Execution: scope → plan → iterate → deliver (papers, open-source, patents, internal wins).
- Communication & collaboration: explain complex work to varied audiences; cross-discipline work.
- Culture/LP fit: ownership, bias for action, frugality, customer/impact obsession.
Be explicit about your contribution. For each project: problem → gap → idea → method → evidence → limitations → next steps → impact.
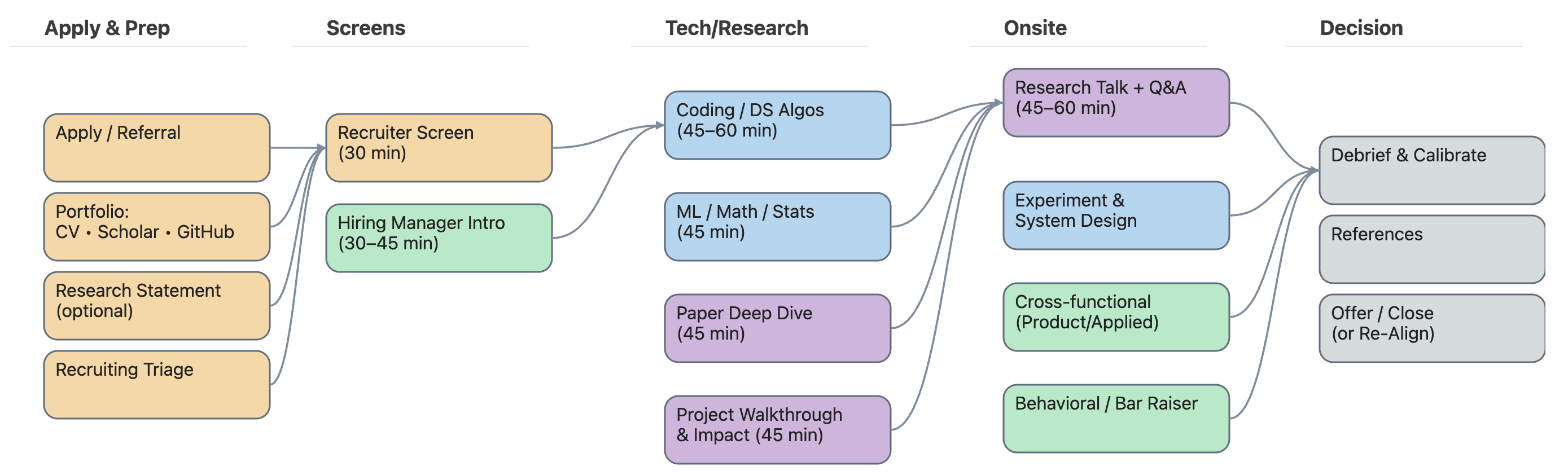
Interview process at a glance
Typical stages
1) Recruiter + HM intro → 2) Tech/Research screens (coding, ML/math, paper deep dive) →
3) Onsite: research talk, systems/experimentation design, cross-functional, behavioral/bar raiser →
4) Debrief → offer.
(Use the SVG diagram you generated earlier or embed it with .)
Preparation timeline (6–8 weeks)
Weeks 1–2: Foundations & portfolio - Curate 2–3 flagship projects; write 1-page project briefs (problem, novelty, 3 results, open questions). - Refresh ML math: gradients, likelihoods, bias–variance, generalization, off-policy vs on-policy RL. - DS&A 20–30 mins/day (arrays, hash maps, trees, graphs, DP—medium level). - Draft talk outline; collect figures; start a reproducible repo.
Weeks 3–4: Research talk + deep dives - Build slides (30/45/60 min versions). Timebox: Motivation 10% → Method 35% → Evidence 40% → Limits + Roadmap 15%. - Prepare ablation stories and negative results; design a live error analysis demo if feasible. - Mock talks with labmates; iterate twice.
Weeks 5–6: Systems & coding polish - 5 case studies: online inference, data pipelines, eval at scale, safety/guardrails, monitoring. - Practice 6–8 coding problems in 60-min sessions; review idioms (two-pointers, heap, BFS/DFS, topo sort). - Draft answers for 8–10 behavioral prompts using STAR(L).
Week 7+: Company-specific tuning - Read team papers/repos; align your roadmap slide to their charter. - Prepare 8–12 questions to ask (below). - Dry run full onsite (talk + 3 interviews + behavioral) in a single sitting.
Research portfolio deep dive
For each project, be ready to answer: - Gap: What prior SOTA did not address? Why now? - Assumptions: Distributional, structural, or operational assumptions—how validated? - Method: Key design choices (loss, architecture, training regime, priors/constraints). - Evidence: Metrics that matter (with CIs); strongest ablation; hardest failure case. - Impact: External adoption, dataset/code release, internal KPI movement, patents. - Next: What would you do with 3 months & a small team?
Artifacts checklist - 10–12 figure slide deck (vector PDFs), 1-page PDF overview, GitHub README with quickstart, repro seed + script.
Technical machine learning knowledge (what to refresh)
- RL: policy gradient theorem; advantage estimation; PPO/TRPO constraints; off-policy (DQN/TD3/SAC); safe RL & constraints; exploration vs exploitation; eval instability & seeding.
- Deep learning: optimization (warmup, cosine decay, AdamW), regularization (dropout, mixup, label-smoothing), attention/transformers, LoRA/parameter-efficient finetuning.
- Statistics & probabilistic modeling: MLE/MAP; conjugacy; posterior predictive; calibration (ECE), uncertainty (epistemic vs aleatoric); A/B testing pitfalls.
- Generative models: diffusion schedule & guidance, VAEs ELBO, GAN stability.
- LLMs: instruction tuning, RAG retrieval quality, eval (exact match, nDCG, win-rates), toxicity & safety filters, hallucination mitigation.
- Vision/multimodal: contrastive learning, detection/segmentation metrics (mAP, IoU), data augmentations.
ML systems & experimentation design
5-step template 1. Clarify goal (user KPI ↔︎ technical metric; online vs offline).
2. Data (sources, labeling strategy, noise, sampling, privacy).
3. Model & infra (baseline → candidate → serving path; latency, cost, reliability).
4. Evaluation (offline metrics + counterfactual replays + online guardrails; slicing).
5. Risk & safety (bias, misuse, red-teaming, rollback plan, observability).
Example prompt (outline answer)
“Design a near real-time anomaly detector for a power grid substation.”
- KPI: reduce outage MTTR by 20%; constraints: <200 ms latency, 99.9% uptime.
- Data: PMU/SCADA streams; label via weak supervision + operator tags.
- Baseline: statistical thresholds; Model: streaming autoencoder + EWMA residuals.
- Eval: ROC-AUC offline, time-to-detect, false alarms/day; shadow deploy → phased rollout.
- Safety: fail-open; human-in-the-loop; drift detector; incident playbook.
Coding & algorithmic skills
- Aim for clean, correct, then optimal. Speak invariants, test cases, and complexity out loud.
- Patterns to practice: two-pointers, sliding window, monotonic stack, BFS/DFS, topological sort, binary search on answer, Dijkstra/Union-Find, prefix sums, DP on sequences/trees.
- ML-adjacent coding: vectorized NumPy, PyTorch modules/forward pass, dataloaders, batching, mixed precision, sanity checks.
Research talk: structure & slides
Slide budget (45 min talk + Q&A) - Title & takeaway (1), Motivation (2), Problem/Gap (2), Method (5), Results (6), Ablations (3), Error analysis (2), Limits (1), Roadmap/fit (2).
Dos - One idea per slide; consistent color for your method; readable axes; include n and CI.
- Put the thesis of each slide in the title: “Physics constraints cut violations by 38% at same cost.”
Don’ts - Crowded plots, cherry-picked examples, unanchored qualitative claims, tiny captions.
Behavioral: STAR + research flavors
Use STAR: Situation, Task, Action, Result, Learning.
Prepare 6 stories: conflict, failure, leadership without authority, speed vs quality, mentoring, cross-team project.
Example prompt
“Tell me about a time your experiment invalidated a roadmap item.”
- S/T: critical Q3 milestone hinged on SOTA surpassing baseline.
- A: pre-registered analysis; ran holdout; flagged negative lift; proposed minimal viable alternative.
- R: saved ~6 wks eng time; reallocated to data quality; shipped smaller win.
- L: add “early stop” gates; improved pre-mortem checklist.
Recommended resources
- Papers: recent NeurIPS/ICLR/ICML tracks relevant to the team; read 2–3 team papers.
- Books: Designing Machine Learning Systems (Huyen), Deep Learning (Goodfellow), ESL (HTF), Probabilistic ML (Barber/Murphy).
- Practice: LeetCode medium sets; pair-program ML design prompts; mock talks.
Example technical & research questions
- Summarize the core contribution of your latest paper in two sentences.
- Which ablation most strongly supports your claim? Which one failed and why?
- How would you adapt your method under 10× less data? Under severe shift?
- What is your evaluation blind spot today? How would you close it?
- Explain epistemic vs. aleatoric uncertainty with a concrete modeling choice.
- For PPO, where does instability come from and how do you diagnose it?
- Design a reliable RAG system for safety-critical queries—retrieval, scoring, guardrails, and evaluation.
“Ask the interviewer”
Use the set that best fits the team. If time is short, ask the Top 3 in each block.
Hiring Manager (core, any research team)
- Top 3
- What research bets matter most in the next 6–12 months, and how will you measure success?
- What makes a “hell-yes” hire here after 90 days? What work would signal that?
- How do ideas transition from a paper/prototype to production or a public result?
- How is impact recognized—publications, product metrics, patents, internal adoption?
- What are examples of projects that didn’t land? Why, and what changed afterward?
- Where are the biggest data/infra bottlenecks that a new scientist can unlock?
Research Scientists (peer scientists)
- Top 3
- Which canonical datasets/eval harnesses are used for your area? How are baselines enforced?
- What’s a recent ablation or negative result that changed your roadmap?
- How do you share/replicate experiments (internal tooling, seeds, result store)?
- How are collaborations formed across teams? Any “platform” teams I should align with?
- What’s the cadence for paper reviews, reading groups, and internal talks?
Engineers / MLEs (production & infra)
- Top 3
- What are the serving constraints (latency, throughput, cost) and reliability SLOs?
- What’s the path from notebook → feature store → online eval → rollout/rollback?
- How do you monitor drift and failures in the wild? What’s the on-call/ownership model?
- What’s the CI/CD story for models (gating tests, shadow, canary, A/B infra)?
- What would you change in our current stack if you could?
PM / Cross-functional (applied impact)
- Top 3
- Which decision or workflow actually changes if this model improves by X%?
- What is the single metric you’d show leadership to justify continued investment?
- What risks (safety, bias, misuse) keep you up at night for this application?
- Where does data come from and how does quality/coverage limit the roadmap?
Recruiter / Compensation
- Level targeting and calibration—what evidence best demonstrates readiness for this level?
- Publication & open-source policy (authors, timing, preprints), conference travel norms.
- Visa/relocation timeline; expected hire start window and interview re-try policy.
Example Domain-specific
If the team is RL / Control (energy, robotics, autonomy)
- What control horizon & loop latency are assumed (e.g., 200 ms, 1 s)? Any hard real-time constraints?
- How are safety constraints enforced (e.g., physics-informed losses, shielded RL, reachability)?
- What are the reference environments (e.g., CityLearn/PowerGym, IEEE 13/34/123 bus, HIL)?
How do sim-to-real gaps show up, and how do you mitigate them (domain randomization, calibration)? - Which offline evaluation and counterfactual replay methods are trusted before online trials?
- What’s the bar for replacing a heuristic/OPF with an RL policy (guardrails, rollback, audits)?
If the team is LLM / RAG / GenAI
- Retrieval stack: index type, chunking, rerankers, eval (nDCG, recall@k, answer faithfulness).
- Hallucination budget & safety: filters/guardrails, red-teaming, and incident handling.
- Finetuning strategy: SFT/LoRA vs. prompt-only; distillation plans; model/versioning policy.
- What constitutes “win” in offline eval vs. human eval? How do you resolve conflicts?
- Data governance: PII/PHI handling, dedup, license compliance, auto-eval for drift.
If the team is Vision / Multimodal
- Canonical datasets & metrics (COCO mAP, IoU, retrieval R@k); how are domain shifts handled?
- Labeling strategy & quality control; synthetic data or augmentation policies.
- Deployment constraints: throughput on edge vs. server; quantization/compilation toolchain.
- Failure modes that matter most (false positives/negatives, OOD, adversarial artifacts).
If you only have time for 3 questions (universal)
- Strategy: What is the one result you’d want me to deliver in 6 months that proves this hire was a “yes”?
- Execution: What is the critical bottleneck (data, infra, evaluation) preventing faster progress today?
- Fit: Which strengths would make me the complement to the current team’s skills?
Checklists
Day-before technical Interview
- Talk readiness: 30/45/60-min versions; 1-sentence thesis; clearly mark your contributions.
- Ablations & limits: 1 strongest ablation you can defend; 1 negative result and what it taught you.
- Paper deep dives: be ready to derive the key equation/algorithm; compare to 2 baselines with numbers.
- Math/ML refresh: RL (policy gradient, GAE, PPO/TRPO intuition), DL (optimizers, regularization), stats (MLE vs MAP, bias–variance, eval metrics).
- Coding drills: 2 timed mediums using core patterns (two-pointers, BFS/DFS, heap, topo sort, DP); practice test-first pseudocode.
- Systems prompts: outline 3 cases (data → model → eval → guardrails → rollout) you can walk through crisply.
- Q&A bank: 10 answers you can deliver fast (assumptions, failure modes, robustness, scalability, safety).
Day-of Interview
- Open strong: restate problem + constraints; define the success metric before proposing solutions.
- Reasoning first: outline 2–3 approaches; justify trade-offs; state target time/space complexity.
- Coding round: implement incrementally; speak invariants and edge cases; analyze complexity after passing tests.
- Research talk: show the central figure; defend an ablation; admit a limitation and the next experiment.
- Design/experimentation: baseline → candidate → eval plan; define slices; propose risks & rollback.
- Close each round: 30–60s recap with decision, trade-offs, and “next step” you’d run.
Offer, Debrief & Negotiation
1) Right after the loop
- Keep a short brag doc: 5–8 bullets tying your work to measurable impact (citations, benchmarks, improvements).
- Send thank-you notes; ask the recruiter for decision timeline and whether the team needs any follow-ups (extra slides, code pointers).
2) Debrief (if you don’t get detailed feedback)
- Ask for 3 bullets: (i) strengths that stood out, (ii) top concern, (iii) what would change the decision next time.
- If there’s a miscalibration (e.g., level/scope), propose a targeted follow-up (short tech screen or focused deep dive).
3) Offer review (when it comes)
- Break it down: base + bonus + equity/RSUs (grant, vesting, refreshers) + sign-on + extras (compute budget, conference travel, publication policy, patent bonus).
- Clarify: level, title, team mandate, location policy, start date, performance review cycles, and conference/OSS policies.
4) Negotiation (impact-first)
- Anchor with scope & impact (what you can deliver in 6–12 months), plus comparables (peer offers or market data for the same level/geo).
- Prioritize asks (pick 2–3):
sign-on/equity/level/research budget/conf travel.
- Sample script:
“Given the scope (X) and the impact I’m positioned to deliver (Y), I’m targeting total comp of Z at level L. If level is fixed, increasing equity by A or adding a B sign-on would bridge the gap. I’d also value C (e.g., conference travel commitment).”
5) Timelines
- If you need time: “I’m very excited. To make a well-considered decision, could we set a reply date of
? I want to complete one pending loop and compare scopes fairly.” - If there’s an exploding deadline, ask for a short extension in exchange for a firm decision date and clear intent.
6) If rejected
- Request specific growth areas and ask whether a re-interview window (e.g., 6 months) with a targeted bar (e.g., systems/experiments) is possible.
Mentorship
If you’d like feedback on your talk, paper deep dive, or a full mock onsite, reach me at cs.kundann@gmail.com.