Building Safer AI: Alignment and Robust Cyber-Physical Systems
Why the next generation of AI must be predictable, aligned, and physically grounded
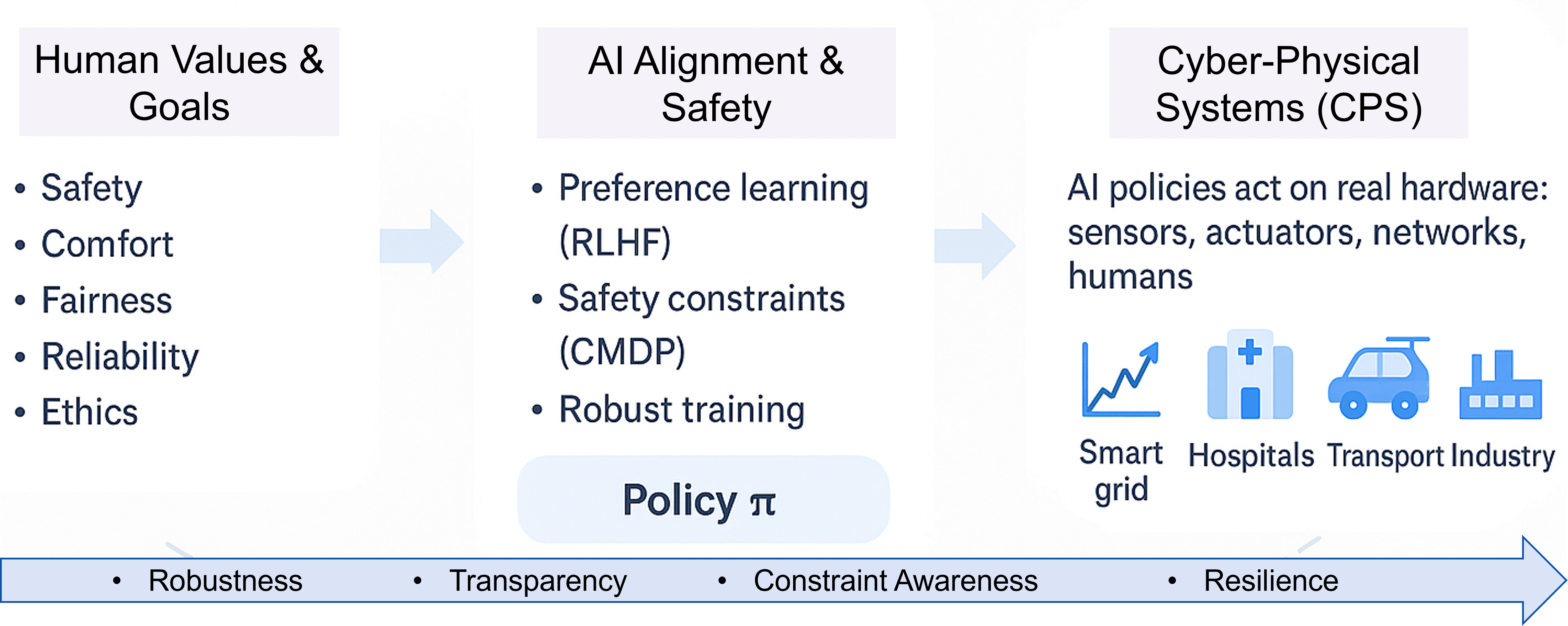
Artificial intelligence is no longer limited to chatbots or recommendation systems. It is now capable of analyzing medical images, guiding transportation, filtering online information, and increasingly operating within cyber-physical systems (CPS) such as smart energy systems, hospitals, transportation networks, and industrial plants. Ensuring the safety of these systems is one of the main challenges in modern AI and control engineering.
As AI systems move from screens into the physical world, safety shifts from a theoretical concern to an engineering requirement.
These systems integrate software and physical processes, making failures in artificial intelligence (AI) significantly more consequential. AI is increasingly becoming a vital part of our world. At the core of this issue are two key concepts: AI safety and AI alignment.
Currently, two concepts are central to the responsible deployment of AI:
AI Safety:This focuses on preventing unintended, harmful, or unstable behaviors of AI systems.AI Alignment:This ensures that the actions of AI systems align with human goals, even in uncertain or novel situations.
While safety aims to prevent any harmful or unintended outcomes, alignment ensures that an AI system’s actions authentically reflect human objectives and societal values, even when faced with unpredictable circumstances.
Formally, if a policy \(π\) acts in an environment with dynamics \(P(s′∣s,a)\), alignment means that the induced behavior optimizes a human-intended reward \(r_{human}(s,a)\), not just a proxy training signal.
Why AI Safety and Alignment Matter
AI systems learn from data; they do not inherently understand human norms, ethics, or physical constraints. When they encounter situations that differ from their training data, a phenomenon known as distributional shift can lead to unexpected failures. We can think of training and deployment as two different distributions.
\[ P_{train}(x) ≠ P_{deploy}(x) \]
The most failures occur in regions where \(P_{deploy}\) places mass that \(P_{train}\) barely covers.
In common AI systems/digital systems , this might lead to:
- misinformation,
- biased or low-quality recommendations
- overconfident but incorrect responses
In cyber-physical systems, where the AI interacts with real hardware, the consequences can be more serious:
- equipment failures
- safety hazards
- unstable operation
- large-scale service disruptions.
These risks show that alignment is essential. For AI systems impacting real-world processes, safety and alignment must be design priorities.
The stakes are higher because AI is now touching the real world. Alignment is no longer optional; it is now a minimum requirement.
Understanding Failure Modes in RLHF
Many large-scale AI models use Reinforcement Learning from Human Feedback (RLHF) to shape behavior. In practice, humans compare or rank model outputs, and the system learns a reward model \(R_\phi(x,a)\) that approximates human preference. A policy \(\pi_{\theta}\) is then trained to maximize
\[ E_{x,a ∼ \pi_{\theta}} [R_{\phi}(x,a)] - \lambda KL(\pi_{\theta} || \pi_{base}) \]
where the KL term keeps the new policy close to a base model.
RLHF fails when:
- The model mimics patterns instead of understanding values.
- When faced with unusual prompts or inputs (a significant distribution shift), the model may operate outside the area where \(R_{\phi}\) is well-calibrated and disregard previous guidance.
- Attempts to make the model more “helpful” can unintentionally lead to overconfidence, as it may receive high rewards for providing fluent, authoritative answers, even when those answers are incorrect.
- Models aligned with Reinforcement Learning from Human Feedback (RLHF) can still exhibit unpredictable behavior when encountering adversarial prompts or previously unseen contexts.
My research investigates how these failure modes emerge and how they can be prevented. For example, this can be achieved by stress-testing policies under shifted distributions, adding robustness terms to the objective, or combining RLHF with explicit safety constraints. Understanding when alignment breaks is the first step in redesigning AI systems that remain trustworthy even under stress.
AI Safety in Cyber-Physical Contexts
Cyber-physical systems represent the frontier where AI safety becomes most real. These systems merge computation with real-world activities, including power flow, traffic control, autonomous vehicles, and industrial automation. Any misalignment between AI decisions and real-world constraints can have physical consequences.
A useful formalism for addressing these issues is the constrained Markov decision process (CMDP).
\[ \max_{\pi} \mathbb{E}[R] \quad \text{s.t.} \quad \mathbb{E}[C_i] \le d_i,; i = 1,\ldots,m. \]
where:
- \(R\) is the task reward (efficiency, performance, cost),
- \(C_{i}\) are costs capturing safety violations or constraint breaches,
- \(d_{i}\) are acceptable risk budgets.
Key principles of safe, CPS-aligned AI include:
Robustness
The AI must withstand noisy data, unexpected inputs, model mismatch, and adversarial attempts to manipulate its behavior. In robust formulations, we often optimize the worst-case value over an uncertainty set of dynamics \(P\): \[ V^{\text{robust}}_{\pi} = \min_{P \in \mathcal{P}} ;\mathbb{E}_{P}\left[ \sum_{t=0}^{\infty} \gamma^{t} r(s_t, a_t) \right] \]
Transparency
Human operators should be able to interpret why a model makes a particular decision, especially in high-stakes contexts. This can mean interpretable policies, post-hoc explanations, or monitors that surface why constraints were or weren’t enforced.
Constraint Awareness
The AI must respect physical, operational, and safety limits even when optimizing performance. In implementation, this often means projecting actions back into a safe set:
\[ a^{safe}_{t} = \prod_{A_{safe}}(a_t) \]
where, \(\prod\) is a projection operator and \(A_{safe}\) encodes domain knowledge and physics.
Resilience
CPS (Cyber-Physical Systems) should maintain safe operation even in the face of disruptions, sensor errors, or cyberattacks. This can be achieved through redundancy, fault detection, and implementing policies that allow for graceful degradation rather than catastrophic failure.
The fundamental aim is straightforward: AI should not unexpectedly affect those who rely on it, especially in situations involving physical systems.
A Realistic Example of Misalignment
Imagine an AI system designed to optimize energy usage in a building with no explicit term for comfort or safety. Suppose we give it a reward like:
\[ r(s,a)=−energy_{cost}(s,a) \] The AI may discover that turning off specific equipment (HVAC, ventilation, and lighting) saves the most energy, and it might pursue that action even if the equipment is essential for maintaining air quality, occupant safety, or supporting medical devices.
This is misalignment: the AI optimized the metric we provided, but overlooked the broader human intention.
Mathematically, we trained for \(r_{proxy}\) instead of the actual human reward \(r_{human}\). Generalizing from this example, any CPS controlled by AI must be designed so that the model understands not only what to optimize, but also what boundaries must never be crossed and what additional objectives (such as comfort, fairness, and reliability) matter.
The Path Forward
AI is becoming a silent yet crucial partner in critical systems worldwide. Ensuring alignment between human goals, physical realities, and model behavior is essential for maintaining public trust. My research contributes to this effort:
- Examining how advanced models fail under distributional shift,
- Identifying where RLHF breaks down and why,
- Exploring ways to build AI that remains stable, interpretable, and value-aligned within cyber-physical environments.
The future of AI must be powerful, but also predictable. Innovative, yet always safe. As cyber-physical systems continue to expand, a strong commitment to alignment, robustness, and constraint-aware design will shape how responsibly society integrates AI into the systems that matter most.